ABSTRACT
The emergence of online communities as a means of lifelong learning beyond traditional educational institutions has led to a significant increase in the availability of discourse data. However, as the dataset grows, the manual examination and analysis of large datasets can be cost-prohibitive. Researchers can use computational methods to understand online communities’ dynamics. Natural Language Processing (NLP) has been demonstrated as a viable solution for analyzing large datasets in educational contexts. This paper explored applying dynamic topic modeling methods to understand users’ informal learning within an AI painting community. We used a classical time-based Latent Dirichlet Allocation (LDA) method and generated a BERT-related model. Using over 180,000 conversation data points, our findings provided insight into what topics participants are interested in and changes among topics. This research aids in understanding the nature of the learning of AI technology and patterns of informal learning happening in online communities.
Keywords
1. INTRODUCTION
Rapid advancements in artificial intelligence (AI) have sparked extensive public discourse. More AI applications have impacted people’s lives, including education and healthcare [29]. Due to the novelty of AI, formal learning environments such as classrooms have limited materials available for learners to access AI [22].
As an alternative, social media has emerged as a crucial source of learning about AI. Reddit and YouTube, for instance, are where people find the most recent AI-related information. Reddit is an online discussion forum that allows users to post questions and responses on subreddits organized by topic [1]. According to [12], Reddit is an online portal for affinity spaces, which enables individuals with shared interests to congregate and exchange information. Users’ discussion about AI painting on Reddit is a self-regulated learning process [3].
AI painting has gained significant attention and sparked intense debates within the online community. Researchers have developed a series of AI literacy [20, 21]. However, there is a gap between experts’ opinions and the nature of learning by learners. Using a bottom-up method, we can explore AI literacy from the learners’ side by investigating individuals’ interests in AI painting. One possible way is to better understand individuals’ informal learning about AI by looking at what they discussed in the online community. The online community provides a convenient platform for experts and novices to participate in discussions on AI [12].
Researchers collected 2k posts and comments and manually coded them into eight categories in previous research [3]. However, 2k is a relatively small amount of data in comparison to the daily average of over 1,000 posts and comments in the Reddit channel. When data continuously grows, it becomes impractical for researchers to code each line manually. Natural language processing (NLP) may offer solutions for scaling up data to obtain a comprehensive view of larger-sized data sets.
This research serves two primary objectives. Firstly, it focuses on utilizing Natural Language Processing (NLP) techniques to enhance our comprehension of affinity spaces and individuals’ self-regulated learning within these spaces. We aim to extract valuable insights from massive online discussions and compare unsupervised, machine-developed, and human-developed coding results by employing dynamic topic modeling. Secondly, the study contributes to understanding the topic dynamics surrounding public interest in AI painting within an online affinity space. Through NLP methods, we seek to aid researchers and educators in discerning the prevalent AI-related subjects that capture the public’s attention.
2. LITERATURE REVIEW
2.1 Online Forum as Informal Learning Space
Online forums have been a prominent informal learning resource. Unlike formal learning, which occurs within the confines of a traditional educational setting, informal learning happens outside the standardized framework and lacks structure [10]. Reddit, for instance, is an online "affinity space" [12] that provides a platform for individuals to communicate and engage in discussions centered around topics of shared interest.
Online affinity spaces provide rich supplementary learning materials [26]. Individual learners generate a huge amount of available resources in these spaces [12]. Discussions between learners and other knowledgeable individuals have transformed into a new learning resource format that novice learners can independently access [27]. This enables novice learners to gather information and knowledge about the topic quickly [17].
In addition to informal learning, online affinity spaces have the potential to impact formal learning positively. These spaces can function as a group driven by knowledge and expertise, allowing students to apply their newfound understanding in a real-world context [19].
However, online affinity spaces, primarily hosted on social media sites, also present risks and challenges, such as access to harmful information and a lack of trust among teenagers [24]. Nevertheless, they offer learners a unique opportunity for interest-based learning outside of the classroom and contribute to the development of their identity [2, 23].
2.2 AI Literacy as Domain Knowledge
The advent of artificial intelligence (AI) is transforming human life. This change brings a new need for literacy in AI [20]. AI literacy is "a set of competencies that enables individuals to critically evaluate AI technologies and communicate and collaborate effectively with AI" [20].
The current AI literacy frameworks developed by researchers are expert-based and utilize a top-down strategy [20, 21]. Long et al. developed 17 competencies around "what is AI," "what can AI do," "how does AI work," "how should AI be used," and "how do people perceive AI."[20]
Learners’ interest in AI is still under research. In previous studies, researchers have collected and hand-coded 2,200 posts and comments on AI painting from a single Subreddit into eight topics: algorithms and models, application, data, ethics and social implications, hardware, entertainment, and off-task discussion [3]. However, 2,200 lines may not provide a representative sample of the discussions due to the large content generated on the subreddit (an average of 1,000 daily posts and comments). This paper proposes utilizing topic modeling techniques on a larger dataset to overcome selection bias and gain a comprehensive understanding of the community discourse.
2.3 Dynamic Topic Modeling as Methods
The development of NLP enables researchers to analyze vast amounts of data. According to [8], NLP is "a collection of theory-driven computational techniques for the automatic analysis and representation of human languages." This paper focuses on one subfield of NLP, topic modeling.
Topic modeling is an unsupervised machine learning approach for uncovering and characterizing latent topics in extensive collections of text documents [9]. It employs Bayesian inference to identify the underlying themes in a corpus of text data [9]. One prominent example of a topic modeling algorithm is Latent Dirichlet Allocation (LDA).
Topic modeling has been applied in various educational fields, such as knowledge and skill set analysis [15], bibliometric study [7], and code discovery in qualitative research [6, 13]. Dynamic topic modeling has been used to identify thematic patterns in large collections of text data [30] but has received limited attention compared to traditional topic modeling techniques. Recent studies have demonstrated the utility of DTM in fields such as communication and public perception analysis [5, 25], providing valuable insights for the proposed method.
Dynamic topic modeling [4] offers a dynamic understanding of given data by extending the LDA model to dynamic corpora, enabling the examination of how topics evolve [4]. DTM models the generation of each document in a time-series corpus as a dynamic mixture of topics, where the mixture weights change over time. For example, it could present how new topics in the data appear or disappear over time [4]. This article aims to discover the evolving pattern of topics that emerged from participants’ discussions on AI painting.
Considering these findings and based on the identified gaps in the literature, this study seeks to address the following research questions:
- What topics are most discussed in the AI painting affinity space?
- How have topics changed in the AI painting learning community over two months?
- What are the differences and similarities between a human-developed coding scheme and an NLP-developed coding scheme?
3. METHODS
This research follows the paradigm of case study [11]. With the help of computational methods of collecting and analyzing data, this research uses multiple measures to conduct a case study in r/StableDiffusion to explore the big picture of an AI painting learning community.
We used textual mining to address our RQ 1-3. We examined the textual compositions in both posts and comments, employing BERTopic—a machine-driven approach—to identify the overarching themes among users. Initially, our process started with data preprocessing procedures, wherein we cleaned the textual content with the Natural Language Toolkit (NLTK) package. After this, we generated a BERT model through the BERTOPIC Python package, which enabled us to identify emergent topics and thematic patterns within the discourse. To further enrich the semantic representations of textual entities, we employed the ’all-MiniLM-L6-v2’ variant of the SentenceTransformer for embedding extraction. Dimensionality reduction was subsequently performed using the UMAP algorithm. Using the K-Means clustering technique, we delineated coherent topic clusters. Additionally, we capitalized on the CountVectorizer for tokenization, followed by the computation of TF-IDF scores to construct robust topic representations.
3.1 Data Collection
For our research, data was collected from the subreddit r/Stable Diffusion, a highly frequented platform for discussions surrounding AI-generated paintings. Utilizing the Pushshift API, all posts and comments were obtained within a specific time frame, from November 7th, 2022, to January 8th, 2023. 14,319 posts and 172,770 comments were included in the sample.
Before we collected data from Reddit through API, we submitted the Determination of Human Subjects Research Form. We got approval from the Institutional Research Board (IRB) to exempt this research. We also anonymized the usernames and other sensitive information for data privacy.
3.2 Data Analysis
Comments were removed if they were not associated with posts within the designated time frame. All posts were concatenated based on their title, context, and comments and treated as a single document. This step integrates the different elements of each post into a single unit, providing a more comprehensive representation of the content.
Time series analysis was conducted on the number of posts, comments, and subscribers of the r/StableDiffusion over two months (9 weeks). It indicates an increase in subscribers from 80,000 to 116,000 at a steady rate. Furthermore, the time series plot of comments revealed three peaks during two months. The first peak occurred during the week of Thanksgiving due to the viral spread of AI-generated holiday greeting graphs. The other two peaks occurred two weeks before Christmas. Based on our analysis, we noticed a seasonality of increased comments on weekends instead of a higher frequency of post submissions on weekdays. We conducted text mining and topic modeling using LDA to analyze the data further.
3.3 Parameter Choosing
In employing the Latent Dirichlet Allocation (LDA) model, a pivotal determination pertains to the optimal number of topics to be utilized. By established methodologies outlined in reference [13], our study embarked upon an empirical investigation of topic quality through the lens of a topic coherence metric. Through systematic experimentation encompassing an array of topic counts, including 6, 7, 8, 9, 10, 20, 50, and 100, a discerning analysis revealed the emergence of local extrema at the 8 and 9 topic mark. In our study, we utilized coherence measures UMass and UCI coherence to evaluate how well the terms within each topic co-occur in the document collection. This approach facilitated a comprehensive assessment of the interpretability and semantic coherence of the topics generated by each model. After carefully examining the coherence scores, we choose to use eight as the number of topics.
3.4 Data Visualization
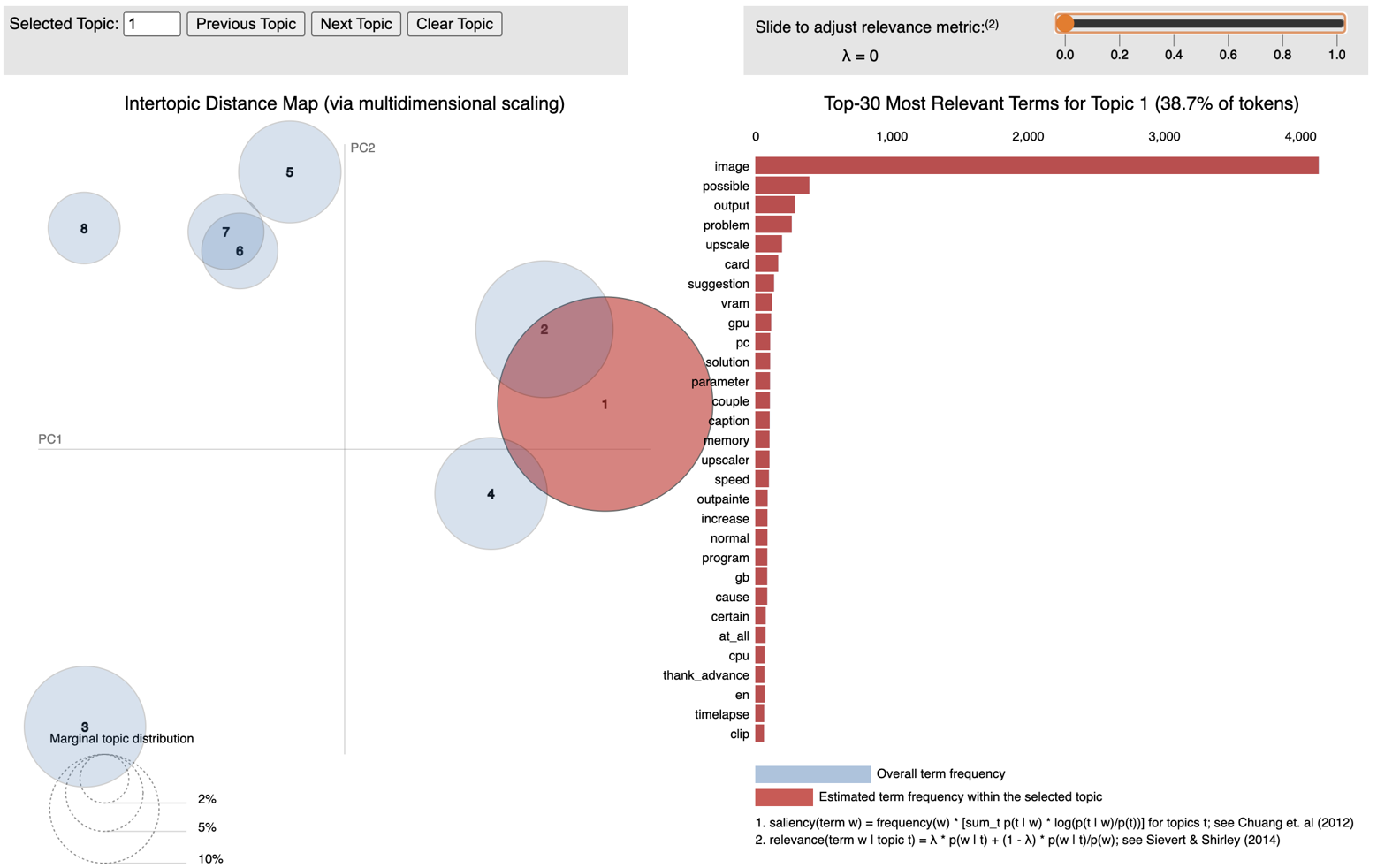
We use LDAvis [28] to visualize the results of DTM. LDAvis is software that visualizes the topic modeling results, as shown in Figure 1. On the left side, a bubble chart denotes each topic in the text. The larger the bubble, the more frequent the topic in the documents. The distance between the topics approximates the semantic relationship between them, and topics that are closer share more common words than other topics far from each other. On the right side, the horizontal bar graph shows keywords related to the topic. The slide bar on the upper side can change the value of \(\lambda \). When you adjust \(\lambda \) to the left, it will decrease the weight of the ratio of the frequency of words given a topic, and when you adjust \(\lambda \) to the right, it will increase the relevance metric, i.e., essential words for a given topic will move up. There is no formula for calculating the optimal value of \(\lambda \); thus, we adjust it based on our domain knowledge of AI painting to better interpret the data. The bar below shows the frequency distribution of the words in the text, and the red-shaded area describes the frequency of each word given a topic. When hovering over the specific words (in the right panel), only the topic containing the phrase is visible, and the size of the bubble in this scenario describes the weight of the word on that topic. The higher the weight of the selected word, the larger the bubble.
4. RESULTS
4.1 RQ1: What are Topics Discussed in the AI Painting Affinity Space?
All data results show that eight topics are most likely to have appeared in the affinity space. As shown in Figure 1, topics 1, 2, and 4 overlap, and topics 5, 6, and 7 overlap. After adjusting \(\lambda \), topic 1 talks more about hardware, such as "gpu", "vram", "pc", "memory", and "cpu". Topic 2 mainly focuses on the ethical issue of AI painting, keywords such as "artists", "community", "job", "company", "open source", and "copyright", are mentioned a lot under the topic. Topic 3 refers to a specific type of content, image sharing, since it contains many kinds of image file names, such as "png", "jpg", "width", "http", and "webp". Topic 4 is related to the discussion of procedures; keywords such as "file", "download", "folder", and "directory" are included. Topics 5 and 6 are close, and their content is similar, including the details and styles of images. Topic 7 focuses more on the application, such as "music", "game", "video", and "meme". Topic 8 mainly discusses the flaws of AI painting, such as its inability to depict details of "fingers" and "eyes."
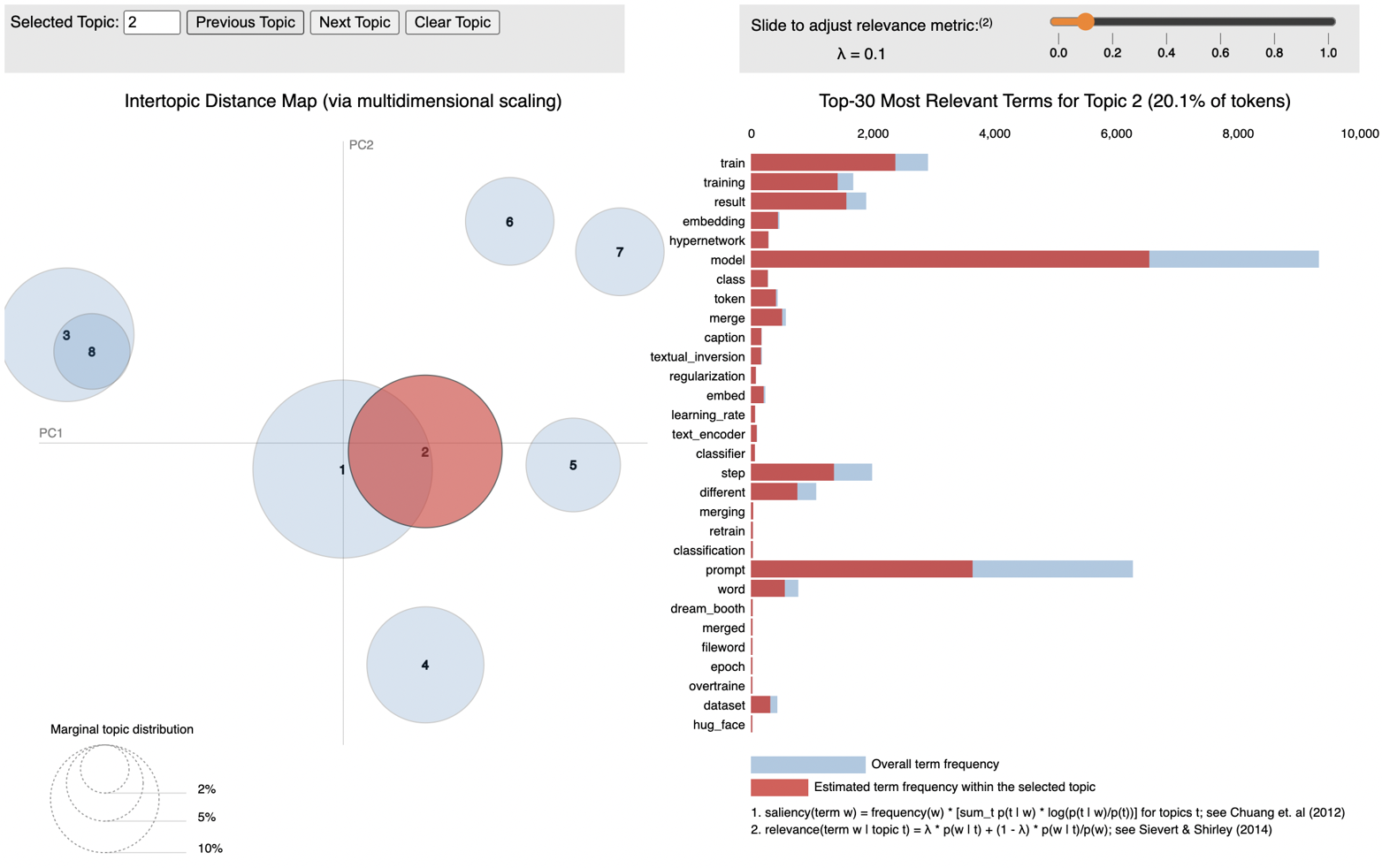
The weekly topic modeling results differ slightly from all data modeling. In our weekly data, we identified eight topics that most possibly appeared in the discussion of AI painting in the affinity space: model training, image processing, installation, image details, image flaws, moral and legal issues, impacts on artists and arts, and hardware. Take week 45 as an example; as shown in Figure 2, image processing (Topic 1) and model training (Topic 2) overlap. Image flaw (Topic 3) is related to image styles (Topic 8).
The results of week 45 topics and primary keywords are shown in Table.1 and Table.2 in the Appendix.
| # | Topic | Keywords |
| 1 | Image processing (\(\lambda =0.1\)) | img, video |
| 2 | Model training (\(\lambda =0.3\)) | train, image |
| 3 | Image flaw (\(\lambda =0.03\)) | ugly, deformed |
| 4 | Installation (\(\lambda =0.2\)) | file, run |
| 5 | Hardware (\(\lambda =0.4\)) | model, gpu |
| 6 | Moral & legal issue (\(\lambda =0.2\)) | debate, porn |
| 7 | Impact on art & artist (\(\lambda =0.2\)) | artist, art |
| 8 | Prompts (\(\lambda =1\)) | woman, water |
4.2 RQ2: How did Topic Change in the AI Painting Affinity Space?
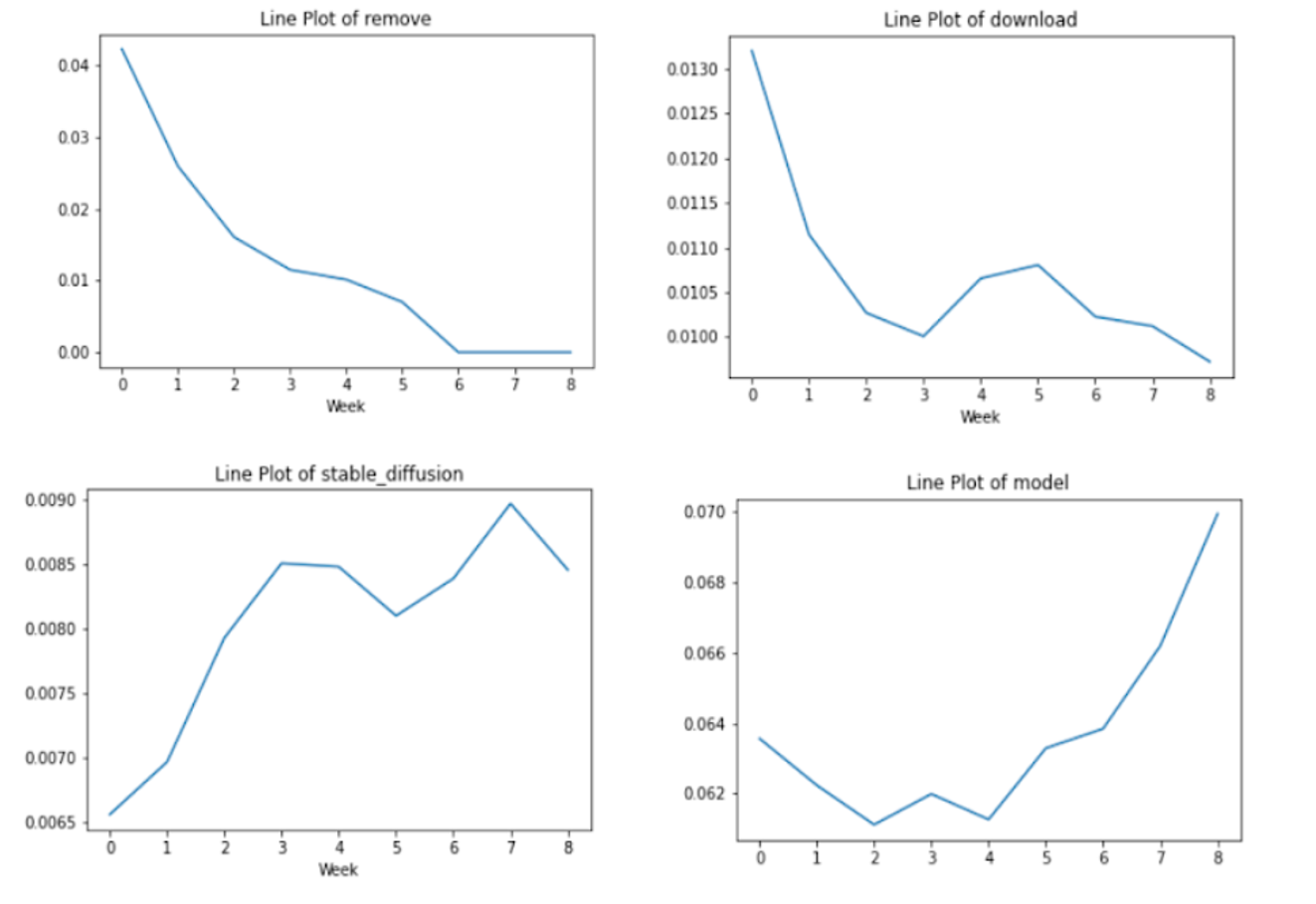
Weekly topics did not vary at the topic level. After nine weeks, eight topics are unchanged. Then, we narrowed the keywords and sought dynamics in the affinity space. As shown in Figure 3, the keywords under each topic in the DTM model constantly evolve, indicating the interests of change in the space.
The first row displays the decreasing trend of keywords such as "remove" and "download" over nine weeks. In the second row, terms such as "Stable Diffusion" and "model" exhibit an upward trend over the past nine weeks. As time went by, there was an increasing hotness in Stable Diffusion itself and models in the space.
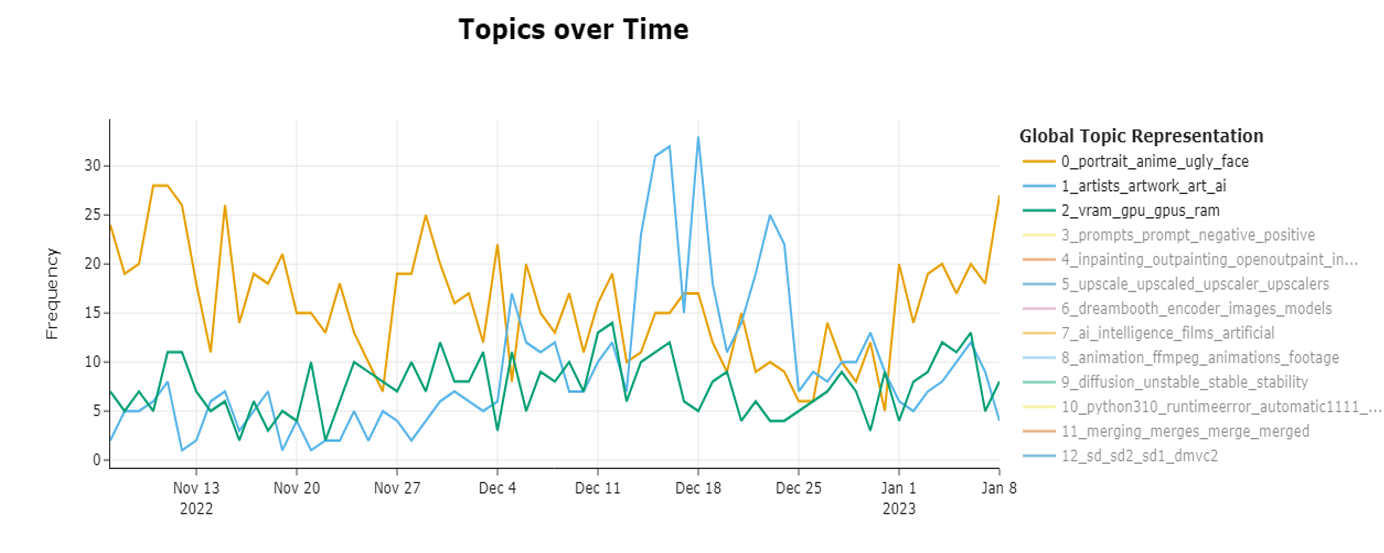
We conducted time series analyses on three different Reddit hot topics. The first topic revolves around discussions related to portraits, anime, and artistic style, with keywords including "portrait," "anime," and "art." This topic exhibits a steady number of posts daily, depicted by a yellow line, which gradually declines until January 1st, followed by a rapid increase after that. The second topic focuses on AI ethics, with keywords like "artists," "artwork," and "copyright." This topic demonstrates a consistent trend, with a notable peak between December 11th and 25th. The third topic centers on hardware discussions, featuring keywords such as "vram," "gpu," and "Nvidia." Unlike the previous topics, this one shows a steady trend with no seasonality or events, reflecting consistent engagement. These analyses provide insights into the dynamics of Reddit discussions. Learners’ engagement with such topics reflects their techniques, ethics, and hardware interests.
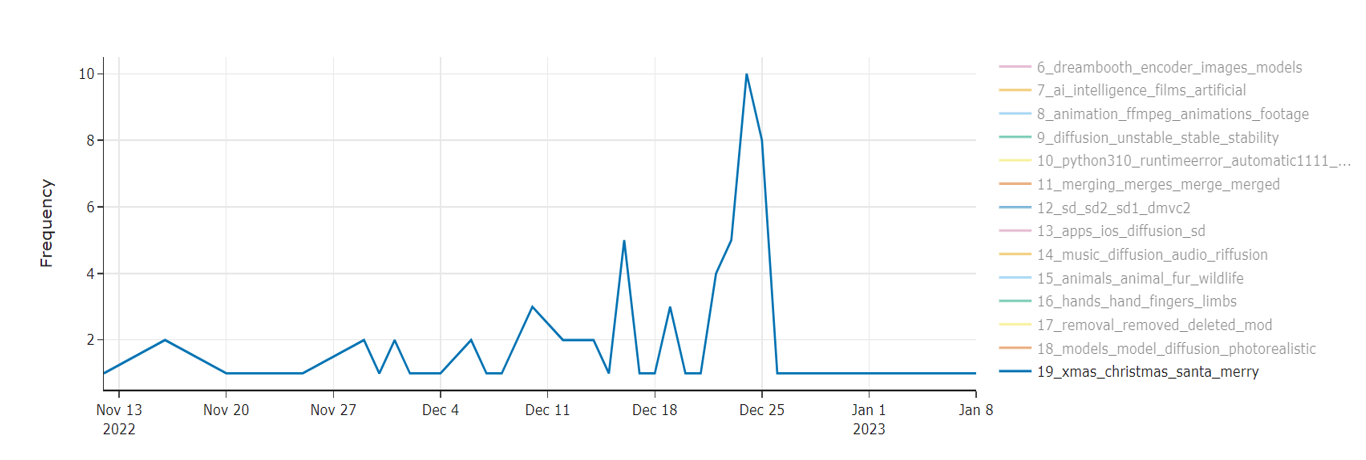
Our time series analyses of the Topic “Christmas” observed a distinct seasonal pattern centered around the holiday. The absence of a trend indicates that the data does not exhibit a consistent long-term increase or decrease over nine weeks. A notable feature is the peak in activity preceding Christmas, followed by a rapid decline to baseline levels immediately after the holiday. This pattern suggests a temporary surge in interest or activity related to Christmas, such as online discussions about Christmas-related AI painting on Reddit.
4.3 RQ3: What are the Differences and Similarities between Human-developed and Machine-generated Topics?
We noticed similarities and differences between human-developed topics and machine-generated topics. An overlap between DTM results and hand-coded topics appeared in the comparison. Six similar topics emerged in both results: models, procedures (how to use AI painting tools), data (details of images and how to prompt AI painting tools), hardware, application, and ethics.
DTM is grounded in textual data. In the weekly data, two distinct machine-developed topics are subsumed by human-developed topics. Human-developed results summarize “moral and legal issues” and “impact on art and artists” as "ethics and social implications." In human-developed topics, all discussions about images were classified as "data," whereas DTM classified them as "image processing," "AI-generated image flaw," and "prompts." In addition, topic modeling identified two distinct software installation and usage procedures. However, entertaining and off-task content on human-developed topics was ignored in the DTM results. One keyword of entertaining content, “meme,” is included in the topic of image processing.
5. DISCUSSIONS
5.1 Enduring Topics and Interests
DTM is utilized to highlight enduring interests in the AI painting affinity space. In the AI painting affinity space, participants actively discussed topics such as AI painting modeling training, software installation, flaws of AI-generated images, how to prompt AI to generate images, moral and legal issues related to AI painting, procedures for AI-generated images, AI painting’s impacts on art, artists, and society, and required hardware of using AI painting.
Topics identified by AI connect back to the developed AI literacy framework. In the informal learning environment, learners ask practical questions and share hands-on experiences with AI. For example, in [20], there is limited discussion on how to work with AI daily, while learners’ discussions in the subreddit space center around practical tips and tutorials on using AI, from purchasing hardware to installing software and interacting with the AI painting. In other words, learners in the Subreddit focused on "using AI," while the AI literacy framework focused on "AI-literate." Future AI literacy frameworks might also consider incorporating learners’ or users’ needs to interact with AI.
5.2 Dynamic Updates and Interaction
AI painting affinity space displays a dynamic daily ambiance within the relatively stable subject matter. In an average of one thousand daily posts and comments, participants share their new works with others and debate their opinions on various topics. These posts and comments constitute the daily updates of the affinity space, making it simple for newcomers to join the discussions. These updates introduce news and information about AI outside of AI painting into space. For example, when chatGPT was released, keywords like "chatGPT" emerged. These updates link members of the affinity space to the greater world.
Affinity space is grounded in participants’ everyday lives. From the dynamics of Christmas, participants actively shared their Christmas special artworks and prompts, combining their learning, working with AI, and celebrating the festival in the space. By leveraging historical data and time series analysis techniques, we can forecast the effect of holidays and events on online community discussions with specific topics, including holiday-themed artwork, to engage users effectively on online platforms like Reddit.
5.3 Inappropriate Content and Ethics Conflicts
In addition to identifying informative content, topic modeling also revealed inappropriate content, such as "NSFW (not safe for work)" and "porn," in the discussion forum. Two reasons lead to this result. Firstly, Reddit is an anonymous forum, so individuals can post and reply without being identified. Secondly, this phenomenon has been investigated in human-computer interaction, i.e., humans tend to use inappropriate language to test and respond to artificial intelligence [18].
Ethics conflicts refer to the debates between proponents and opponents of AI painting; they argue about "Do artists benefit from AI painting?" and "Does AI painting steal artists’ work?". Impacts on art/artists and moral/law risks are prominent topics in the affinity space, as determined by topic modeling. When considering online affinity spaces as an informal learning environment, inappropriate content and ethical conflicts are on the other side. Chaos and noise from online forums require formal educators to consider the trade-off of asking students to learn in such communities, particularly adolescents.
5.4 Dynamic Topic Modeling in Understanding Textual Data
In line with previous research on the use of NLP methods in qualitative data analysis [6, 14], our findings show that DTM is a new method that has the potential to help qualitative researchers see the big picture of the data. Echoing [13], our findings show that DTM demonstrates its ability to be grounded in textual data. In the weekly data, three different topics from machine-developed results are under the umbrella of human-developed topics but have more nuances. For example, DTM has two ethics topics: "moral and legal issues" and "impact on art and artists", while human-developed results summarize them into "ethics and social implications". In another case, all image discussions were categorized as "data" in human-developed topics. At the same time, DTM separated them into "image processing," "flaws of AI-generated image," and "details of image." Besides, in procedures, topic modeling identified two different methods: installing and using the software.
DTM is promising to be used to explore and validate human-developed coding schemes in research with large amounts of data. In the early phase of data analysis, DTM can assist researchers in having a different perspective on the data, such as what topics are most likely to appear together in the dataset. When human researchers finish developing the coding scheme, it can also be compared with the results of DTM to see if any data has been missed.
A machine-developed coding scheme has drawbacks in understanding context and humor. Taking entertainment content as an example, an unsupervised machine can only catch text data, such as "memes." This is understandable since NLP methods mainly focus on linguistic meaning. In context, NLP struggles to understand humor and memes [16].
Human intelligence continues to be critical in scaling research, such as when we decide on the number of topics and the value of the visualization of topic modeling results. These observations require the researcher to notice the nuances of the original data, which machines can hardly handle.
5.5 Limitations and Future Research
The data collection for this study was limited to 9 weeks within a single Reddit channel. While the sample size was substantial, extending the data collection over a longer time frame, potentially several months, would have been more advantageous to provide a more comprehensive understanding of the phenomena under investigation. This limitation is acknowledged and serves as a suggestion for future research to consider when expanding upon the findings of this study. Besides, compared with running DTM in all data, the results of running DTM of weekly data show a better representation of the entire context and a better coherence with human-developed topics. More research is needed to explore the reliability and accuracy of the time frame of topic modeling.
6. CONCLUSIONS
This paper used dynamic topic modeling to analyze large-scale discussion data and identify the dynamic pattern in the AI painting affinity space. The dynamic topic enables us to understand better what topics are discussed and how they evolved across time in the affinity space. Besides, DTM and BERT models are promising methods for exploring the use of NLP in the coding process of qualitative research.
7. REFERENCES
- K. E. Anderson. Ask me anything: what is reddit? Library Hi Tech News, 32(5):8–11, July 2015.
- A. Barany and A. Foster. Context, community, and the individual: Modeling identity in a game affinity space. The Journal of Experimental Education, 89(3):523–540, July 2021.
- R. Bi and S. Wei. Exploring the implementation of NLP topic modeling for understanding the dynamics of informal learning in an AI painting community. In Proceedings of the 16th International Conference on Educational Data Mining, EDM 2023, Bengaluru, India, July 11-14, 2023. International Educational Data Mining Society, 2023.
- D. M. Blei and J. D. Lafferty. Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning, ICML ’06, pages 113–120, New York, New York, USA, 2006.
- A. Bogdanowicz and C. Guan. Dynamic topic modeling of twitter data during the covid-19 pandemic. PLOS ONE, 17(5), May 2022.
- Z. Cai et al. Using topic modeling for code discovery in large scale text data. pages 18–31, 2021.
- X. Chen et al. Detecting latent topics and trends in educational technologies over four decades using structural topic modeling: A retrospective of all volumes of computers & education. Computers & Education, 151:103855, July 2020.
- K. R. Chowdhary. Natural language processing. In Fundamentals of Artificial Intelligence, pages 603–649. Springer India, 2020.
- R. Churchill and L. Singh. The evolution of topic modeling. ACM Computing Surveys, 54(10s):1–35, Jan. 2022.
- T. J. Conlon. A review of informal learning literature, theory and implications for practice in developing global professional competence. Journal of European Industrial Training, 28(2/3/4):283–295, Feb. 2004.
- W. J. Creswell and N. C. Poth. Qualitative Inquiry and Research Design: Choosing among Five Approaches. SAGE Publications, Inc., 2016.
- J. P. Gee. Semiotic social spaces and affinity spaces: from the age of mythology to today’s schools. In Beyond Communities of Practice, pages 214–232. Cambridge University Press, 2005.
- B. Gencoglu et al. Machine and expert judgments of student perceptions of teaching behavior in secondary education: Added value of topic modeling with big data. Computers & Education, 193:104682, Feb. 2023.
- S. Geng et al. Understanding the focal points and sentiment of learners in mooc reviews: A machine learning and sc-liwc-based approach. British Journal of Educational Technology, 51(5):1785–1803, Sept. 2020.
- F. Gurcan and N. E. Cagiltay. Big data software engineering: Analysis of knowledge domains and skill sets using lda-based topic modeling. IEEE Access, 7:82541–82552, 2019.
- M. K. Hasan et al. UR-FUNNY: A multimodal language dataset for understanding humor. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 2046–2056, 2019.
- E. R. Hayes and J. P. Gee. Handbook of Public Pedagogy. Routledge, 2010.
- J. Hill et al. Real conversations with artificial intelligence: A comparison between human–human online conversations and human–chatbot conversations. Computers in Human Behavior, 49:245–250, Aug. 2015.
- M. Ito et al. Connected learning: An agenda for research and design. Technical report, Digital Media and Learning Research Hub, 2013.
- D. Long and B. Magerko. What is ai literacy? competencies and design considerations. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pages 1–16, 2020.
- D. T. K. Ng, J. K. L. Leung, S. K. W. Chu, and M. S. Qiao. Conceptualizing ai literacy: An exploratory review. Computers and Education: Artificial Intelligence, 2:100041, 2021.
- T. K. Ng and K. W. Chu. Motivating students to learn ai through social networking sites: A case study in hong kong. Online Learning, 25(1), Mar. 2021.
- E. R. Padgett and J. S. Curwood. A figment of their imagination. Journal of Adolescent & Adult Literacy, 59(4):397–407, Jan. 2016.
- A. Pérez-Escoda et al. Fake news reaching young people on social networks: Distrust challenging media literacy. Publications, 9(2):24, June 2021.
- H. Sha et al. Dynamic topic modeling of the covid-19 twitter narrative among u.s. governors and cabinet executives. Apr. 2020.
- P. Sharma et al. Knowledge sharing discourse types used by key actors in online affinity spaces. Information and Learning Sciences, 122(9/10):671–687, Sept. 2021.
- P. Sharma and S. Land. Patterns of knowledge sharing in an online affinity space for diabetes. Educational Technology Research and Development, 67(2):247–275, Apr. 2019.
- C. Sievert and K. Shirley. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, pages 63–70, 2014.
- P. Stone et al. Artificial intelligence and life in 2030: The one hundred year study on artificial intelligence, Oct. 2016.
- D. Valdez et al. Topic modeling: Latent semantic analysis for the social sciences. Social Science Quarterly, 99(5):1665–1679, Nov. 2018.
APPENDIX
A. HEADINGS IN APPENDICES
A.0.1 Tables
| # | Keywords |
|---|---|
| 1 |
Img, video, animation, area, denoising, upscale, workflow, imagine, sequence, mask, audio, fps, mind, inpaint, photoshop, consistency, mesh, transform, interpolation, editing |
| 2 |
Train, image, result, embedding, hypernetwork, model, class, style, weight, token, merge, subject, embed, step, dataset, textual_inversion, different, prompt, caption, dreambooth |
| 3 |
auto_webp, format_png, ugly, deformed, poorly_draw, sampler_scale_seed_size„ fuse_finger, sampler_scale, bad_proportion, trend_artstation, extra_limb, face_mutation, low_quality, long_neck, miss_finger, cinematic_lighting, disfigure, bad_anatomy |
| 4 |
File, run, load, download, error, install, version, folder, ckpt, extension, python, command, installation, cuda, pickle, script, directory, code, update, restart, click, path, local |
| 5 |
Free, pay, money, card, release, service, cost, open_source, cheap, run, time, app, buy, price, fast, speed, model, gpu, hardware, vram, product |
| 6 |
Remove, debate, porn, people, abuse, content, mod, harm, moral, drama, legal, lawyer, legally, NSFW, hate, public, attack, post, child, subreddit, discussion, ban, censor, government, politician, censorship, illegal, claim |
| 7 |
Artist, art, people, human, work, commission, argument, copyright, job, automation, steal, theft, capitalism, skill, technology, tool, learn |
| 8 |
Woman, water, realistic, line, stand, face, painting, full, blue, style, photo, man, stable_diffusion_webui, portrait, shot, prompt, eye, skin, detailed, body, hair, wear, photography |
A.0.2 Figures