ABSTRACT
Large language models (LLMs), such as Codex, hold great promise in enhancing programming education by automatically generating feedback for students. We investigate using LLMs to generate feedback for fixing syntax errors in Python programs, a key scenario in introductory programming. More concretely, given a student’s buggy program, our goal is to generate feedback comprising a fixed program along with a natural language explanation describing the errors/fixes, inspired by how a human tutor would give feedback. While using LLMs is promising, the critical challenge is to ensure high precision in the generated feedback, which is imperative before deploying such technology in classrooms. The main research question we study is: Can we develop LLMs-based feedback generation techniques with a tunable precision parameter, giving educators quality control over the feedback that students receive? To this end, we introduce \(\relax \textsc {PyFiXV}\), our technique to generate high-precision feedback powered by Codex. The key idea behind \(\relax \textsc {PyFiXV}\) is to use a novel run-time validation mechanism to decide whether the generated feedback is suitable for sharing with the student; notably, this validation mechanism also provides a precision knob to educators. We perform an extensive evaluation using two real-world datasets of Python programs with syntax errors and show the efficacy of \(\relax \textsc {PyFiXV}\) in generating high-precision feedback.
Keywords
1. INTRODUCTION
Large language models (LLMs) trained on text and code have the potential to power next-generation AI-driven educational technologies and drastically improve the landscape of computing education. One of such popular LLMs is OpenAI’s Codex [1], a variant of the \(175\) billion parameter model GPT-3 [2], trained by fine-tuning GPT-3 on code from over \(50\) million GitHub repositories. A recent study ranked Codex in the top quartile w.r.t. students in a large introductory programming course [3]. Subsequently, recent works have shown promising results in using Codex on various programming education scenarios, including generating new programming assignments [4], providing code explanations [5], and enhancing programming-error-messages [6].
We investigate the use of LLMs to generate feedback for programming syntax errors, a key scenario in introductory programming education. Even though such errors typically require small fixes and are easily explainable by human tutors, they can pose a major hurdle in learning for novice students [7]. Moreover, the programming-error-messages provided by the default programming environment are often cryptic and unable to provide explicable feedback to students [8–10]. Ideally, a human tutor would help a novice student by providing detailed feedback describing the errors and required fixes to the buggy program; however, it is extremely tedious/challenging to provide feedback at scale given the growing enrollments in introductory programming courses [11, 12]. To this end, our goal is to automate the feedback generation process using LLMs-based techniques.
More concretely, given a student’s buggy program, we want to generate feedback comprising a fixed program and a natural language explanation describing the errors/fixes, inspired by how a human tutor would give feedback. While models like Codex, trained on both text and code, are naturally suitable for this, the critical challenge is to ensure high precision in the generated feedback. High precision is imperative in building educators’ trust before deploying such an AI-driven technology in classrooms. A recent work investigated enhancing the default programming-error-messages using Codex [6]; one of the takeaways, quoted from their paper, is “The key implications of this work are that programming error message explanations and suggested fixes generated by LLMs are not yet ready for production use in introductory programming classes...”. Our initial experiments (Section 4) also highlight issues in generating high-precision feedback. To this end, the main research question is:
Can we develop LLMs-based feedback generation techniques with a tunable precision parameter, giving educators quality control over the feedback that students receive?
1.1 Our Approach and Contributions
In this paper, we develop \(\relax \textsc {PyFiXV}\), our technique to generate high-precision feedback powered by Codex. Given a student’s buggy program as input, \(\relax \textsc {PyFiXV}\) decomposes the overall process into (i) feedback generation (i.e., a fixed program and a natural language explanation for errors/fixes); and (ii) feedback validation (i.e., deciding whether the generated feedback is suitable for sharing with the student). One of the key ideas in \(\relax \textsc {PyFiXV}\) is to use a run-time feedback validation mechanism that decides whether the generated feedback is of good quality. This validation mechanism uses Codex as a simulated student model – the intuition is that a good quality explanation, when provided as Codex’s prompt instruction, should increase Codex’s success in converting the buggy program to the fixed program. Notably, this validation also provides a tuneable precision knob to educators to control the precision and coverage trade-off. The illustrative examples in Figures 1, 2, and 3 showcase \(\relax \textsc {PyFiXV}\) on three different student’s buggy programs. Our main contributions are:
- (I)
- We formalize the problem of generating high-precision feedback for programming syntax errors using LLMs, where feedback comprises a fixed program and a natural language explanation. (Section 2)
- (II)
- We develop a novel technique, \(\relax \textsc {PyFiXV}\), that generates feedback using Codex and has a run-time feedback validation mechanism to decide whether the generated feedback is suitable for sharing. (Section 3)
- (III)
- We perform extensive evaluations using two real-world datasets of Python programs with syntax errors and showcase the efficacy of \(\relax \textsc {PyFiXV}\). We publicly release the implementation of \(\relax \textsc {PyFiXV}\). (Section 4)1
1.2 Related Work
Feedback generation for programming errors. There has been extensive work on feedback generation for syntactic/semantic programming errors [13–17]; however, these works have focused on fixing/repairing buggy programs without providing explanations. The work in [11] proposed a technique to generate explanations; however, it requires pre-specified rules that map errors to explanations. Another line of work, complementary to ours, has explored crowdsourcing approaches to obtain explanations provided by other students/tutors [18, 19]. There has also been extensive work on improving the programming-error-messages by designing customized environments [9, 10]. As discussed earlier, a recent study used Codex to enhance these error messages [6]; however, our work is different as we focus on generating high-precision feedback with a tuneable precision knob.
Validation of generated content. In recent work, [20] developed a technique to validate LLMs’ output in the context of program synthesis. While similar in spirit, their validation mechanism is different and operates by asking LLMs to generate predicates for testing the synthesized programs. Another possible approach is to use back-translation models to validate the generated content [21, 22]; however, such a back-translation model (that generates buggy programs from explanations) is not readily available for our setting. Another approach, complementary to ours, is to use human-in-the-loop for validating low confidence outputs [23].



2. PROBLEM SETUP
Next, we introduce definitions and formalize our objective.
2.1 Preliminaries
Student’s buggy program. Consider a student working on a programming assignment who has written a buggy program with syntax errors, such as shown in Figures 1a, 2a, and 3a. Formally, these syntax errors are defined by the underlying parser of the programming language [13]; we will use the Python programming language in our evaluation. Henceforth, we denote such a buggy program as \(\relax \mathcal {P}_{\textnormal {b}}\), which is provided as an input to feedback generation techniques.
Feedback style. Given \(\relax \mathcal {P}_{\textnormal {b}}\), we seek to generate feedback comprising a fixed program along with a natural language explanation describing the errors and fixes. This feedback style is inspired by how a human tutor would give feedback to novice students in introductory programming education [5, 9]. We denote a generated fixed program as \(\relax \mathcal {P}_{\textnormal {f}}\), a generated explanation as \(\relax \mathcal {X}\), and generated feedback as a tuple \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\).
Feedback quality. We assess the quality of generated feedback \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) w.r.t. \(\relax \mathcal {P}_{\textnormal {b}}\) along the following binary attributes: (i) \(\relax \mathcal {P}_{\textnormal {f}}\) is syntactically correct and is obtained by making a small number of edits to fix \(\relax \mathcal {P}_{\textnormal {b}}\); (ii) \(\relax \mathcal {X}\) is complete, i.e., contains information about all errors and required fixes; (iii) \(\relax \mathcal {X}\) is correct, i.e., the provided information correctly explains errors and required fixes; (iv) \(\relax \mathcal {X}\) is comprehensible, i.e., easy to understand, presented in a readable format, and doesn’t contain redundant information. These attributes are inspired by evaluation rubrics used in literature [6, 25–27]. In our evaluation, feedback quality is evaluated via ratings by experts along these four attributes. We measure feedback quality as binary by assigning the value of \(1\) (good quality) if it satisfies all the four quality attributes and otherwise \(0\) (bad quality).2
2.2 Performance Metrics and Objective
Performance metrics. Next, we describe the overall performance metrics used to evaluate a feedback generation technique. For a buggy program \(\relax \mathcal {P}_{\textnormal {b}}\) as input, we seek to design techniques that generate feedback \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) and also decide whether the generated feedback is suitable for sharing with the student. We measure the performance of a technique using two metrics: (i) Coverage measuring the percentage number of times the feedback is generated and provided to the student; (ii) Precision measuring the percentage number of times the provided feedback is of good quality w.r.t. the binary feedback quality criterion introduced above. In our experiments, we will compute these metrics on a dataset \(\relax \mathbb {D}_{\textnormal {test}}\) = {\(\relax \mathcal {P}_{\textnormal {b}}\)} comprising a set of students’ buggy programs.3
Objective. Our goal is to design feedback generation techniques with high precision, which is imperative before deploying such techniques in classrooms. In particular, we want to develop techniques with a tuneable precision parameter that could provide a knob to educators to control the precision and coverage trade-off.
3. OUR TECHNIQUE PYFIXV
In this section, we present \(\relax \textsc {PyFiXV}\), our technique to generate high-precision feedback using LLMs. \(\relax \textsc {PyFiXV}\) uses OpenAPI’s Codex as LLMs [1] – Codex has shown competitive performance on a variety of programming benchmarks [1, 3, 16, 17], and is particularly suitable for \(\relax \textsc {PyFiXV}\) as we seek to generate both fixed programs and natural language explanations. More specifically, \(\relax \textsc {PyFiXV}\) uses two access points of Codex provided by OpenAI through public APIs: Codex-Edit [28] and Codex-Complete [29]. As illustrated in Figure 4, \(\relax \textsc {PyFiXV}\) has the following three components/stages: (1) generating a fixed program \(\relax \mathcal {P}_{\textnormal {f}}\) by editing \(\relax \mathcal {P}_{\textnormal {b}}\) using Codex-Edit; (2) generating natural language explanation \(\relax \mathcal {X}\) using Codex-Complete; (3) validating feedback \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) using Codex-Edit to decide whether the generated feedback is suitable for sharing. The overall pipeline of \(\relax \textsc {PyFiXV}\) is modular and we will evaluate the utility of different components in Section 4. Next, we provide details for each of these stages.
3.1 Stage-1: Generating Fixed Program
Given a student’s buggy program \(\relax \mathcal {P}_{\textnormal {b}}\) as input, \(\relax \textsc {PyFiXV}\)’s Stage-1 generates a fixed program \(\relax \mathcal {P}_{\textnormal {f}}\). We use Codex-Edit for fixing/repairing the buggy program in this stage since it has shown to be competitive in program repair benchmarks in recent works [30]. Figure 5a shows a sample prompt used by \(\relax \textsc {PyFiXV}\) to query Codex-Edit for the buggy Python \(3\) program in Figure 2a. The process of generating \(\relax \mathcal {P}_{\textnormal {f}}\) is determined by two hyperparameters: (i) \(t_1 \in [0.0, 1.0]\) is the temperature value specified when querying Codex-Edit and controls stochasticity/diversity in generated programs; (ii) \(n_1\) controls the number of queries made to Codex-Edit.
More concretely, \(\relax \textsc {PyFiXV}\) begins by making \(n_1\) queries to Codex-Edit with temperature \(t_1\). Then, out of \(n_1\) generated programs, \(\relax \textsc {PyFiXV}\) selects \(\relax \mathcal {P}_{\textnormal {f}}\) as the program that is syntactically correct and has the smallest edit-distance to \(\relax \mathcal {P}_{\textnormal {b}}\). Here, edit-distance between two programs is measured by first tokenizing programs using Pygments library [31] and then computing Levenshtein edit-distance over token strings.4 If Stage-1 is unable to generate a fixed program, the process stops without generating any feedback; see Footnote 3. In our experiments, we set \((t_1=0.5, n_1=10)\) and obtained a high success rate of generating a fixed program \(\relax \mathcal {P}_{\textnormal {f}}\) with a small number of edits w.r.t. \(\relax \mathcal {P}_{\textnormal {b}}\).
3.2 Stage-2: Generating Explanation
Given \(\relax \mathcal {P}_{\textnormal {b}}\) and \(\relax \mathcal {P}_{\textnormal {f}}\) as inputs, \(\relax \textsc {PyFiXV}\)’s Stage-2 generates a natural language explanation \(\relax \mathcal {X}\) describing errors/fixes. We use Codex-Complete in this stage as it is naturally suited to generate text by completing a prompt [1, 5, 6]. A crucial ingredient of Stage-2 is the annotated dataset \(\relax \mathbb {D}_{\textnormal {shot}}\) used to select few-shot examples when querying Codex-Complete (see Figure 4). Figure 5b shows a sample prompt used by \(\relax \textsc {PyFiXV}\) to query Codex-Complete for the scenario in Figure 2. In Figure 5b, line4–line6 indicate three few-shot examples (not shown for conciseness), line9–line19 provides \(\relax \mathcal {P}_{\textnormal {b}}\), line23–line30 provides \(\relax \mathcal {P}_{\textnormal {f}}\) in the form of line-diff w.r.t. \(\relax \mathcal {P}_{\textnormal {b}}\), and line33 is the instruction to be completed by Codex-Complete. Given a prompt, the process of generating \(\relax \mathcal {X}\) is determined by two hyperparameters: (i) a temperature value \(t_2\) (\(=0\)) and (ii) the number of queries \(n_2\) (\(=1\)). Next, we discuss the role of \(\relax \mathbb {D}_{\textnormal {shot}}\) in selecting few-shots examples.
When querying Codex-Complete, we use three few-shot examples selected from \(\relax \mathbb {D}_{\textnormal {shot}}\), an annotated dataset of examples comprising buggy programs and desired feedback obtained by expert annotations (see Section 4.2). These annotated examples essentially provide a context to LLMs and have shown to play an important role in optimizing the generated output (e.g., see [1, 2, 16, 17, 32]). In our case, \(\relax \mathbb {D}_{\textnormal {shot}}\) provides contextualized training data, capturing the format of how experts/tutors give explanations. Given \(\relax \mathcal {P}_{\textnormal {b}}\) and \(\relax \mathcal {P}_{\textnormal {f}}\), we use two main criteria to select few-shot examples. The primary criterion is to pick examples where the error type of buggy program in the example is same as that of \(\relax \mathcal {P}_{\textnormal {b}}\)—the underlying parser/compiler provides error types (e.g., ‘InvalidSyntax’, ‘UnexpectedIndent’). The secondary criterion (used to break ties in the selection process) is based on the edit-distance between the diff of buggy/fixed program in the example and diff of \(\relax \mathcal {P}_{\textnormal {b}}\)/\(\relax \mathcal {P}_{\textnormal {f}}\). In Section 4, we conduct ablations to showcase the importance of selecting few-shots.
3.3 Stage-3: Validating Feedback
Given \(\relax \mathcal {P}_{\textnormal {b}}\) and \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) as inputs, \(\relax \textsc {PyFiXV}\)’s Stage-3 validates the feedback quality and makes a binary decision of “accept” (feedback is suitable for sharing) or “reject” (feedback is discarded). \(\relax \textsc {PyFiXV}\) uses a novel run-time feedback validation mechanism using Codex-Edit to decide whether the feedback \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) w.r.t. \(\relax \mathcal {P}_{\textnormal {b}}\) is of good quality. Here, Codex-Edit is used in the flipped role of a simulated student model – the intuition is that a good quality explanation \(\relax \mathcal {X}\), when provided in Codex-Edit’s prompt instruction, should increase Codex-Edit’s success in converting \(\relax \mathcal {P}_{\textnormal {b}}\) to \(\relax \mathcal {P}_{\textnormal {f}}\). Figure 5c shows a sample prompt used by \(\relax \textsc {PyFiXV}\) to query Codex-Edit for the scenario in Figure 2—see the caption on how “Instructions for Codex-Edit” in Figure 5c is obtained.5
The validation mechanism has three hyperparameters: (i) \(t_3 \in [0.0, 1.0]\) is the temperature value specified when querying Codex-Edit; (ii) \(n_3\) controls the number of queries made to Codex-Edit; (iii) \(h_3 \in [1, n_3]\) is the threshold used for acceptance decision. More concretely, \(\relax \textsc {PyFiXV}\) begins by making \(n_3\) queries to Codex-Edit with temperature \(t_3\). Then, out of \(n_3\) generated programs, \(\relax \textsc {PyFiXV}\) counts the number of programs that don’t have syntax errors and have an exact-match with \(\relax \mathcal {P}_{\textnormal {f}}\). Here, exact-match is checked by converting programs to their Abstract Syntax Tree (AST)-based normalized representations.6 Finally, the validation mechanism accepts the feedback if the number of exact matches is at least \(h_3\). These hyperparameters \((t_3, n_3, h_3)\) also provide a precision knob and are selected to obtain the desired precision level, as discussed next.
3.4 Precision and Coverage Trade-Off
\(\relax \textsc {PyFiXV}\)’s validation mechanism provides a precision knob to control the precision and coverage trade-off (see performance metrics in Section 2.2). Let \(\relax \textnormal {P}\) be the desired precision level we want to achieve for \(\relax \textsc {PyFiXV}\). The idea is to choose Stage-3 hyperparameters \((t_3, n_3, h_3)\) that achieve \(\relax \textnormal {P}\) precision level. For this purpose, we use a calibration dataset \(\relax \mathbb {D}_{\textnormal {cal}}\) for picking the hyperparameters. More concretely, in our experiments, \(\relax \textsc {PyFiXV}\) first computes performance metrics on \(\relax \mathbb {D}_{\textnormal {cal}}\) for the following range of values: (i) \(t_3 \in \{0.3, 0.5, 0.8\}\); (ii) \(n_3 \in \{10\}\); (iii) \(h_3 \in \{1, 2, \ldots , 10\}\). Then, it chooses \((t_3, n_3, h_3)\) that has at least \(\relax \textnormal {P}\) precision level and maximizes coverage; when achieving the desired \(\relax \textnormal {P}\) is not possible, then the next lower possible precision is considered. The chosen values of hyperparameters are then used in \(\relax \textsc {PyFiXV}\)’s Stage-3 validation mechanism. We refer to \(\relax \textsc {PyFiXV}\)\(_{P \geq x}\) as the version of \(\relax \textsc {PyFiXV}\) calibrated with \(P \geq x\).


4. EXPERIMENTAL EVALUATION
We perform evaluations using two real-world Python programming datasets, namely TigerJython [9] and Codeforces [24]. We picked Python because of its growing popularity as an introductory programming language; notably, \(\relax \textsc {PyFiXV}\) can be used with other languages by appropriately changing the prompts and tokenizers used. We use OpenAI’s public APIs for Codex-Edit [28] (model=code-davinci-edit-001) and Codex-Complete [29] (model=code-davinci-002). We begin by describing different techniques used in the evaluation.
4.1 Baselines and Variants of PYFIXV
Default programming-error-messages without validation. As our first baseline, \(\relax \textsc {PyFi-PEM}\) uses \(\relax \textsc {PyFiXV}\)’s Stage-1 to generate \(\relax \mathcal {P}_{\textnormal {f}}\) and uses programming-error-messages provided by the programming environment as \(\relax \mathcal {X}\). \(\relax \textsc {PyFi-PEM}\) uses error messages provided by Python \(2.7\) environment for TigerJython and Python \(3.12\) environment for Codeforces. This baseline is without validation (i.e., the generated feedback is always accepted).
Variants of \(\relax \textsc {PyFiXV}\) without validation. \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Sel}}\) is a variant of \(\relax \textsc {PyFiXV}\) without the validation mechanism (i.e., only uses Stage-1 and Stage-2). \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Rand}}\) is a variant of \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Sel}}\) where few-shot examples in Stage-2 are picked randomly from \(\relax \mathbb {D}_{\textnormal {shot}}\). \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {None}}\) is a variant of \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Sel}}\) that doesn’t use few-shot examples in Stage-2. \(\relax \textsc {PyFi||X}_{\textnormal {shot:}\textsc {Sel}}\) is a variant of \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Sel}}\) that runs Stage-1 and Stage-2 in parallel; hence, Stage-2’s prompt doesn’t make use of \(\relax \mathcal {P}_{\textnormal {f}}\). All these variants are without validation (i.e., the generated feedback is always accepted).
Techniques with alternative validation mechanisms. We consider two variants of \(\relax \textsc {PyFiXV}\), namely \(\relax \textsc {PyFiX-Rule}\) and \(\relax \textsc {PyFiX-Opt}\), that use different validation mechanisms (i.e., replace \(\relax \textsc {PyFiXV}\)’s Stage-3 with an alternative validation). \(\relax \textsc {PyFiX-Rule}\) validates \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) based on \(\relax \mathcal {X}\)’s length, as noted in Footnote 5. Given a hyperparameter \(h_{r}\), \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\) is accepted if the number of tokens in \(\relax \mathcal {X}\) is at most \(h_{r}\), where tokenization is done by splitting on whitespaces/punctuations. \(\relax \textsc {PyFiX-Rule}\)’s \(h_{r}\) is picked from the set \(\{30, 40, 50, \ldots , 200\}\) based on the desired precision level \(\relax \textnormal {P}\), by following the calibration process in Section 3.4. \(\relax \textsc {PyFiX-Opt}\) uses an oracle validation that has access to expert’s ratings for the generated feedback \(\relax (\mathcal {P}_{\textnormal {f}}, \mathcal {X})\). Then, for a desired \(\relax \textnormal {P}\), \(\relax \textsc {PyFiX-Opt}\) performs optimal validation and highlights the maximum coverage achievable on \(\relax \mathbb {D}_{\textnormal {test}}\) for the generated feedback.
4.2 Datasets and Evaluation Procedure
Datasets and annotations for few-shot examples. As our first dataset, namely TigerJython, we have \(240\) distinct Python \(2\) programs written by students in TigerJython’s educational programming environment [9]. We obtained a private and anonymized version of the dataset used in [34], with string literals in programs replaced with sequences of ‘x’ (e.g., see Figure 1). As our second dataset, namely Codeforces, we curated \(240\) distinct Python \(3\) programs from the Codeforces website using their public APIs [24], inspired by similar works that curate Codeforces dataset [35, 36]. Programs in both datasets have syntax errors and have token length at most \(500\) (see Section 3.1 about program tokenization). For the Codeforces dataset, we only include programs submitted to contests held from July 2021 onwards (after the cut-off date for Codex’s training data [1]). Since a part of these datasets will be used for few-shot examples (as \(\relax \mathbb {D}_{\textnormal {shot}}\) in \(\relax \textsc {PyFiXV}\)’s Stage-2), we asked experts to annotate these \(480\) programs with feedback (i.e., a fixed program along with an explanation). Three experts, with extensive experience in Python programming and tutoring, provided annotations.
Evaluation procedure and feedback ratings. Given a dataset \(\relax \mathbb {D}\) with \(240\) buggy programs, we can evaluate a technique by splitting \(\relax \mathbb {D}\) as follows: (a) \(\relax \mathbb {D}_{\textnormal {test}}\) (\(25\)%) for reporting precision and coverage performance metrics; (b) \(\relax \mathbb {D}_{\textnormal {shot}}\) (\(50\)%) for few-shot examples; (c) \(\relax \mathbb {D}_{\textnormal {cal}}\) (\(25\)%) for calibrating validation mechanism. To report overall performance for techniques, we perform a cross-validation procedure with four evaluation rounds while ensuring that \(\relax \mathbb {D}_{\textnormal {test}}\) across four rounds are non-overlapping. We then report aggregated results across these rounds as average mean (stderr). As discussed in Sections 2.1 and 2.2, evaluating these performance metrics requires feedback ratings by experts to assess the quality of the feedback generated by each technique.7 For example, evaluating metrics on TigerJython dataset for \(\relax \textsc {PyFiXV}\) requires \(480\) feedback ratings (\(4 \times 60\) for \(\relax \mathbb {D}_{\textnormal {test}}\) and \(4 \times 60\) for \(\relax \mathbb {D}_{\textnormal {cal}}\)). To begin, we did a smaller scale investigation to establish the rating criteria, where two experts rated \(100\) generated feedback instances; we obtained Cohen’s kappa reliability value \(0.72\) indicating substantial agreement between experts [37]. Afterward, one expert (with experience in tutoring Python programming classes) did these feedback ratings for the evaluation results.8
4.3 Results
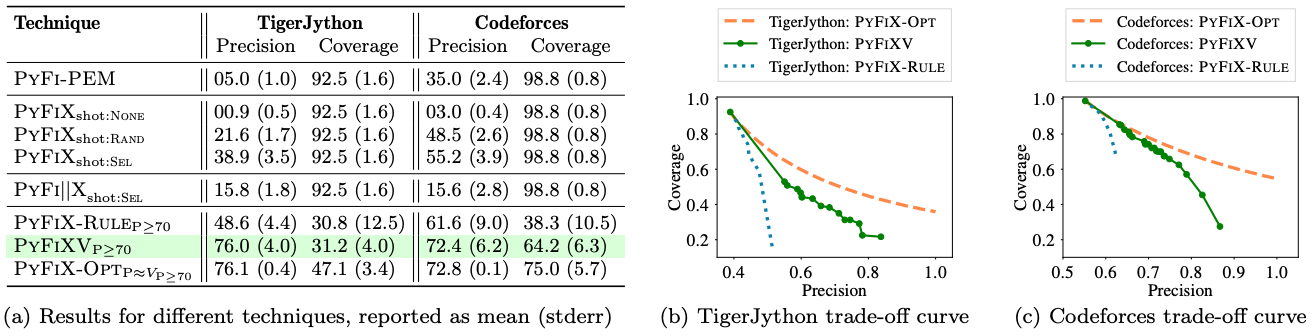
Comparison of different techniques. Figure 6a provides a comparison of different techniques on two datasets. All techniques here use \(\relax \textsc {PyFiXV}\)’s Stage-1 to obtain \(\relax \mathcal {P}_{\textnormal {f}}\). The coverage numbers of \(92.5\) and \(98.8\) reported in Figure 6a correspond to the success rate of obtaining \(\relax \mathcal {P}_{\textnormal {f}}\) on these datasets (the average edit-distance between \(\relax \mathcal {P}_{\textnormal {b}}\) and \(\relax \mathcal {P}_{\textnormal {f}}\) is about \(10.4\) and \(7.5\) tokens on these datasets, respectively). For our baseline \(\relax \textsc {PyFi-PEM}\), we see a big jump in precision from \(5.0\) for TigerJython (Python \(2\)) to \(35.0\) for Codeforces (Python \(3\)), owing to enhanced error messages in recent Python versions [38–40]. Results for \(\relax \textsc {PyFiXV}\)\(_{P\geq 70}\) in comparison with results for \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Sel}}\), \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Rand}}\), \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {None}}\), and \(\relax \textsc {PyFi||X}_{\textnormal {shot:}\textsc {Sel}}\) showcase the utility of different components used in \(\relax \textsc {PyFiXV}\)’s pipeline. Comparing \(\relax \textsc {PyFiXV}\)\(_{P\geq 70}\) with \(\relax \textsc {PyFiX-Rule}\)\(_{P\geq 70}\) shows that \(\relax \textsc {PyFiXV}\)’s validation substantially outperforms \(\relax \textsc {PyFiX-Rule}\)’s validation.9 Lastly, results for \(\relax \textsc {PyFiX-Opt}\)\(_{P\approx {}V_{P\geq 70}}\) are obtained by setting the desired precision level for \(\relax \textsc {PyFiX-Opt}\) to match that of \(\relax \textsc {PyFiXV}\)\(_{P\geq 70}\) on \(\relax \mathbb {D}_{\textnormal {test}}\) – the coverage numbers (\(47.1\) for TigerJython and \(75.0\) for Codeforces) indicate the maximum possible achievable coverage. Notably, \(\relax \textsc {PyFiXV}\)\(_{\geq 70}\) achieves a competitive coverage of \(64.2\) on Codeforces.10
Precision and coverage trade-off curves. The curves in Figures 6b and 6c are obtained by picking different desired precision levels \(\relax \textnormal {P}\) and then computing precision/coverage values on \(\relax \mathbb {D}_{\textnormal {test}}\) w.r.t. \(\relax \textnormal {P}\). The curves for \(\relax \textsc {PyFiX-Opt}\) show the maximum possible coverage achievable on \(\relax \mathbb {D}_{\textnormal {test}}\) for different precision levels \(\relax \textnormal {P}\) using our generated feedback. To obtain these curves for \(\relax \textsc {PyFiXV}\) and \(\relax \textsc {PyFiX-Rule}\), we did calibration directly on \(\relax \mathbb {D}_{\textnormal {test}}\) instead of \(\relax \mathbb {D}_{\textnormal {cal}}\) (i.e., doing ideal calibration for their validation mechanisms when comparing with \(\relax \textsc {PyFiX-Opt}\)’s curves). These curves highlight the precision and coverage trade-off offered by \(\relax \textsc {PyFiXV}\) in comparison to a simple rule-based validation and the oracle validation.
Qualitative analysis. We have provided several illustrative examples to demonstrate our technique \(\relax \textsc {PyFiXV}\). Figures 1, 2, and 7 show examples where \(\relax \textsc {PyFiXV}\)’s Stage-1 and Stage-2 generate good quality feedback and Stage-3 successfully accepts the feedback. Figures 3 and 8 show examples where \(\relax \textsc {PyFiXV}\)’s Stage-1 and Stage-2 generate bad quality feedback and Stage-3 successfully rejects the feedback. Figure 7 highlights that \(\relax \textsc {PyFiXV}\) can make non-trivial fixes in the buggy program and correctly explain them in a comprehensible way. Figure 3 shows an example where the overall feedback is bad quality and successfully rejected, though parts of the generated explanation are correct; this could potentially be useful for tutors in a human-in-the-loop approach.


5. CONCLUDING DISCUSSIONS
We investigated using LLMs to generate feedback for fixing programming syntax errors. In particular, we considered feedback in the form of a fixed program along with a natural language explanation. We focussed on the challenge of generating high-precision feedback, which is crucial before deploying such technology in classrooms. Our proposed technique, \(\relax \textsc {PyFiXV}\), ensures high precision through a novel run-time validation mechanism and also provides a precision knob to educators. We performed an extensive evaluation to showcase the efficacy of \(\relax \textsc {PyFiXV}\) on two real-world Python programming datasets. There are several interesting directions for future work, including (a) improving \(\relax \textsc {PyFiXV}\)’s components to obtain better precision/coverage trade-off, e.g., by adapting our technique to use recent LLMs such as ChatGPT [42] and GPT-4 [43] instead of Codex; (b) extending \(\relax \textsc {PyFiXV}\) beyond syntax errors to provide feedback for programs with semantic errors or partial programs; (c) incorporating additional signals in \(\relax \textsc {PyFiXV}\)’s validation mechanism; (d) conducting real-world studies in classrooms.
6. ACKNOWLEDGMENTS
Funded/Co-funded by the European Union (ERC, TOPS, 101039090). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them.
References
- Mark Chen and et al. Evaluating Large Language Models Trained on Code. CoRR, abs/2107.03374, 2021.
- Tom B. Brown and et al. Language Models are Few-Shot Learners. In NeurIPS, 2020.
- James Finnie-Ansley, Paul Denny, Brett A. Becker, Andrew Luxton-Reilly, and James Prather. The Robots Are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming. In ACE, 2022.
- Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. Automatic Generation of Programming Exercises and Code Explanations Using Large Language Models. In ICER, 2022.
- Stephen MacNeil, Andrew Tran, Arto Hellas, Joanne Kim, Sami Sarsa, Paul Denny, Seth Bernstein, and Juho Leinonen. Experiences from Using Code Explanations Generated by Large Language Models in a Web Software Development E-Book. In SIGCSE, 2023.
- Juho Leinonen, Arto Hellas, Sami Sarsa, Brent N. Reeves, Paul Denny, James Prather, and Brett A. Becker. Using Large Language Models to Enhance Programming Error Messages. In SIGCSE, 2023.
- James Prather, Raymond Pettit, Kayla Holcomb McMurry, Alani L. Peters, John Homer, Nevan Simone, and Maxine S. Cohen. On Novices’ Interaction with Compiler Error Messages: A Human Factors Approach. In ICER, 2017.
- Brett A. Becker. An Effective Approach to Enhancing Compiler Error Messages. In SIGCSE, 2016.
- Tobias Kohn and Bill Z. Manaris. Tell Me What’s Wrong: A Python IDE with Error Messages. In SIGCSE, 2020.
- Brett A. Becker. What Does Saying That ‘Programming is Hard’ Really Say, and About Whom? Communications of ACM, 64(8):27–29, 2021.
- Rishabh Singh, Sumit Gulwani, and Armando Solar-Lezama. Automated Feedback Generation for Introductory Programming Assignments. In PLDI, 2013.
- Samim Mirhosseini, Austin Z. Henley, and Chris Parnin. What is Your Biggest Pain Point? An Investigation of CS Instructor Obstacles, Workarounds, and Desires. In SIGCSE, 2023.
- Sumit Gulwani, Ivan Radicek, and Florian Zuleger. Automated Clustering and Program Repair for Introductory Programming Assignments. In PLDI, 2018.
- Sahil Bhatia, Pushmeet Kohli, and Rishabh Singh. Neuro-Symbolic Program Corrector for Introductory Programming Assignments. In ICSE, 2018.
- Rahul Gupta, Aditya Kanade, and Shirish K. Shevade. Deep Reinforcement Learning for Syntactic Error Repair in Student Programs. In AAAI, 2019.
- Jialu Zhang, José Cambronero, Sumit Gulwani, Vu Le, Ruzica Piskac, Gustavo Soares, and Gust Verbruggen. Repairing Bugs in Python Assignments Using Large Language Models. CoRR, abs/2209.14876, 2022.
- Harshit Joshi, José Pablo Cambronero Sánchez, Sumit Gulwani, Vu Le, Ivan Radicek, and Gust Verbruggen. Repair is Nearly Generation: Multilingual Program Repair with LLMs. In AAAI, 2023.
- Björn Hartmann, Daniel MacDougall, Joel Brandt, and Scott R. Klemmer. What Would Other Programmers Do: Suggesting Solutions to Error Messages. In CHI, 2010.
- Andrew Head, Elena L. Glassman, Gustavo Soares, Ryo Suzuki, Lucas Figueredo, Loris D’Antoni, and Björn Hartmann. Writing Reusable Code Feedback at Scale with Mixed-Initiative Program Synthesis. In Learning @ Scale, 2017.
- Darren Key, Wen-Ding Li, and Kevin Ellis. I Speak, You Verify: Toward Trustworthy Neural Program Synthesis. CoRR, abs/2210.00848, 2022.
- Sergey Edunov, Myle Ott, Michael Auli, and David Grangier. Understanding Back-Translation at Scale. In EMNLP, 2018.
- Yewen Pu, Kevin Ellis, Marta Kryven, Josh Tenenbaum, and Armando Solar-Lezama. Program Synthesis with Pragmatic Communication. In NeurIPS, 2020.
- Hiroaki Funayama, Tasuku Sato, Yuichiroh Matsubayashi, Tomoya Mizumoto, Jun Suzuki, and Kentaro Inui. Balancing Cost and Quality: An Exploration of Human-in-the-Loop Frameworks for Automated Short Answer Scoring. In AIED, 2022.
- Mikhail Mirzayanov. Codeforces.
https://codeforces.com/. - Rui Zhi, Samiha Marwan, Yihuan Dong, Nicholas Lytle, Thomas W. Price, and Tiffany Barnes. Toward Data-Driven Example Feedback for Novice Programming. In EDM, 2019.
- Ahana Ghosh, Sebastian Tschiatschek, Sam Devlin, and Adish Singla. Adaptive Scaffolding in Block-Based Programming via Synthesizing New Tasks as Pop Quizzes. In AIED, 2022.
- Anaïs Tack and Chris Piech. The AI Teacher Test: Measuring the Pedagogical Ability of Blender and GPT-3 in Educational Dialogues. In EDM, 2023.
- OpenAI. Codex-Edit.
https://beta.openai.com/playground?mode=edit&model=code-davinci-edit-001, . - OpenAI. Codex-Ccomplete.
https://beta.openai.com/playground?mode=complete&model=code-davinci-002, . - Zhiyu Fan, Xiang Gao, Abhik Roychoudhury, and Shin Hwei Tan. Automated Repair of Programs from Large Language Models. In ICSE, 2022.
- Georg Brandl, Matthäus Chajdas, and Jean
Abou-Samra. Pygments.
https://pygments.org/. - Rohan Bavishi, Harshit Joshi, José Cambronero, Anna Fariha, Sumit Gulwani, Vu Le, Ivan Radicek, and Ashish Tiwari. Neurosymbolic Repair for Low-Code Formula Languages. Proceedings ACM Programming Languages, 6(OOPSLA2), 2022.
- Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: A Method for Automatic Evaluation of Machine Translation. In ACL, 2002.
- Tobias Kohn. The Error Behind The Message: Finding the Cause of Error Messages in Python. In SIGCSE, 2019.
- Ethan Caballero and Ilya
Sutskever. Description2Code Dataset.
https://github.com/ethancaballero/description2code, 2016. - Yujia Li and et al. Competition-Level Code Generation with AlphaCode. 2022.
- Matthijs J Warrens. Five Ways to Look at Cohen’s Kappa. Journal of Psychology & Psychotherapy, 5(4): 1, 2015.
- The Python Software Foundation. What’s New In
Python 3.10.
https://docs.python.org/3/whatsnew/3.10.html, . - The Python Software Foundation. What’s New In
Python 3.11.
https://docs.python.org/3/whatsnew/3.11.html, . - The Python Software Foundation.
What’s New In Python 3.12.
https://docs.python.org/3.12/whatsnew/3.12.html, . - William G Cochran. The \(\chi \)2 Test of Goodness of Fit. The Annals of Mathematical Statistics, 1952.
- OpenAI. ChatGPT.
https://openai.com/blog/chatgpt, 2023. - OpenAI. GPT-4 Technical Report. CoRR, abs/2303.08774, 2023.
1Github: https://github.com/machine-teaching-group/edm2023_PyFiXV
2We note that the four attributes are independent. In particular, the attribute “complete” captures whether the explanation contains information about all errors/fixes (even though the information could be wrong), and the attribute “correct” captures the correctness of the provided information.
3When a technique cannot generate feedback for an input program \(\relax \mathcal {P}_{\textnormal {b}}\) (e.g., the technique is unable to find a fixed program), then we use a natural convention that no feedback is provided to the student—this convention lowers the coverage metric but doesn’t directly affect the precision metric.
4Note that buggy programs are not parseable to Abstract Syntax Tree (AST) representations and string-based distance is commonly used in such settings (e.g., see [16]).
5In our initial experiments, we tried using alternative signals for validation, such as (a) Codex-Complete’s probabilities associated with generated \(\relax \mathcal {X}\); (b) automatic scoring of \(\relax \mathcal {X}\) w.r.t. explanations in few-shots using BLEU score [33]; (c) filtering based on \(\relax \mathcal {X}\)’s length. Section 4 reports results for (c) as it had the highest performance among these alternatives.
6We check for AST-based exact match instead of checking for Levenshtein edit-distance over token strings being \(0\) (see Section 3.1). AST-based exact match is more relaxed than edit-distance being \(0\) – AST-based representation ignores certain differences between codes, e.g., based on extra spaces and comments. We used the AST-based exact match in the validation mechanism as it is more robust to such differences.
7We note that precision and coverage performance metrics for different techniques are reported for the end-to-end process associated with each technique, and not just for the validation mechanism. Also, even if a technique doesn’t use any validation mechanism, the coverage could be less than \(100.0\) as discussed in Footnote 3.
8We note that the experts were blinded to the condition (technique) associated with each feedback instance when providing ratings. Moreover, these generated feedback instances were given to experts in randomized order across conditions instead of grouping them per condition.
9When comparing \(\relax \textsc {PyFiXV}\)\(_{P\geq 70}\) with these techniques in Figure 6a, the results are significantly different w.r.t. \(\chi ^2\) tests [41] (\(p\leq 0.0001\)); here, we use contingency tables with two rows (techniques) and four columns (\(240\) data points mapped to four possible precision/coverage outcomes).
10Techniques \(\relax \textsc {PyFiX}_{\textnormal {shot:}\textsc {Sel}}\), \(\relax \textsc {PyFiX-Rule}\), \(\relax \textsc {PyFiXV}\)\(_{P\geq 70}\), and \(\relax \textsc {PyFiX-Opt}\)\(_{P\approx {}V_{P\geq 70}}\) differ only in terms of validation mechanisms. We can compare the validation mechanisms used in these techniques based on F1-score. The F1-scores of these four techniques are as follows: \(0.56\), \(0.39\), \(0.70\), and \(0.86\) for TigerJython, respectively; \(0.71\), \(0.47\), \(0.77\), and \(0.84\) for Codeforces, respectively.
© 2023 Copyright is held by the author(s). This work is distributed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) license.