ABSTRACT
Neural networks are ubiquitous in applied machine learning for education. Their pervasive success in predictive performance comes alongside a severe weakness, the lack of explainability of their decisions, especially relevant in human-centric fields. We implement five state-of-the-art methodologies for explaining black-box machine learning models (LIME, PermutationSHAP, KernelSHAP, DiCE, CEM) and examine the strengths of each approach on the downstream task of student performance prediction for five massive open online courses. Our experiments demonstrate that the families of explainers do not agree with each other on feature importance for the same Bidirectional LSTM models with the same representative set of students. We use Principal Component Analysis, Jensen-Shannon distance, and Spearman’s rank-order correlation to quantitatively cross-examine explanations across methods and courses. Furthermore, we validate explainer performance across curriculum-based prerequisite relationships. Our results come to the concerning conclusion that the choice of explainer is an important decision and is in fact paramount to the interpretation of the predictive results, even more so than the course the model is trained on. Source code and models are released at http://github.com/epfl-ml4ed/evaluating-explainers.
Keywords
1. INTRODUCTION
The steep rise in popularity of neural networks has been closely mirrored by the adoption of deep learning for education. For the majority of educational data modeling tasks such as student success prediction (e.g., [14]), estimating early dropout (e.g., [42]), and knowledge tracing (e.g., [35, 2]), the recent literature relies on neural networks to reduce human involvement in the pipeline and boost overall prediction accuracy. Unfortunately, these advances come at a significant cost: traditional machine learning techniques (e.g., linear regression, SVMs, decision trees) are simple, but interpretable, where deep learning techniques trade transparency for the ability to capture complex data representations [28].
There is a compelling need for interpretability in models dealing with human data, especially in education. [41] emphasizes that explainability and accountability should be incorporated in machine learning system design to meet social, ethical and legislative requirements. Other work [7] strongly argues for the necessity of interpretable models in education, specifically in settings where students can see the effect of a decision but not the reasoning behind it (e.g., Open Learner Models). Predictions of student performance are often used to determine underachieving students for targeted downstream interventions. Identifying important features motivating failure or dropout predictions is crucial in designing effective, personalized interventions.
However, there exists only a handful of papers focusing on explainability in the field of machine learning for education. For example, [23] examined the inner workings of deep learning models for knowledge tracing through layer-relevance propagation. Other researchers [13] experimented with traditional machine learning models for student success prediction and implemented local explanations with LIME for transparency in the best performing model. Additionally, [3] used SHAP feature importances to interpret student dropout prediction models. [30] suggested interventions for wheel-spinning students based on Shapley values. Finally, [40] explored LIME on ensemble machine learning methods for student performance prediction, [37] integrated LIME explanations in student advising dashboards, and [34] used LIME for interpreting models identifying at-risk students.
While field of neural network explainability is also nascent in the broader machine learning community, the last five years have shown a sharp increase in research and industry interest in this topic. Local, instance-based explainability methods like LIME [36] and SHAP [24] have become immensely popular. These methods have been successfully applied on models predicting ICU mortality [17], non-invasive ventilation for ALS patients [9], and credit risk [12]. Recent work in counterfactual explanations [29, 18, 8] searches for a minimal subset of features that leads to the prediction alongside a minimal feature subset that needs to be changed for the prediction to change. Counterfactuals have been used in tasks like image classification [11], loan repayment [33], and grouping websites into topics for safe-advertising [27].
Although the explainability corpora is growing, there is a clear gap in explainability literature for education, with an even more pressing need for work (quantitatively) comparing different explainability methods. To the best of our knowledge, current research on explainability in education is exclusively applied: the majority of previous research implements only one specific explainability method to interpret the predictions of their proposed approach.
To address this research gap, we examine and compare five popular instance-based explainability methods on student success prediction models for five different massive open online courses (MOOCs). We formulate comparable feature importance scores for each explainer, scaled between on a uniformly sampled, stratified representative set of students. To quantitatively compare the feature importance distributions, we propose the use of different measures: rank-based metrics (Spearman’s rank-order correlation), distance metrics (Jensen Shannon Distance), and dimensionality analysis (Principal Component Analysis). We validate the explanations through an analysis of feature importance on a MOOC with known prerequisite relationships in the underlying curriculum. With our experiments, we address three research questions: 1) How similar are the explanations of different explainability methods for a specific course (RQ1)? 2) How do explanations (quantitatively) compare across courses (RQ2)? 3) Do explanations align with prerequisite relations in a course curriculum (RQ3)?
Our results demonstrate that the feature importance distributions extracted by different explainability methods for the same model and course differ significantly from each other. When comparing the feature importances across courses, we see that LIME is far apart from all other methods due to selecting a sparse feature set. Furthermore, our findings show that the choice of explainability method influences the feature importance distribution much more than the course the model is predicting on. Our examination on prerequisite relationships between features further indicates that the three families of methods are only partially able to uncover prerequisite dependencies between course weeks. Source code and models are released on Github1.
2. METHODOLOGY

The goal of this paper is to compare explanations from deep learning models tasked with identifying student success prediction in MOOCs. In this section, we formalize the student success prediction task addressed in this paper including the data collection and preprocessing, feature extraction, and model preparation. We then introduce the considered explainability methods and describe the process to extract explanations for student success predictions from a trained model, showcased as feature importance weights.
2.1 Formal Preliminaries
We consider a set of students enrolled in a course part of an online educational offering . Course has a predefined weekly schedule consisting of learning objects from a catalog . Students enrolled in a course interact with the learning objects included in the course schedule, generating a time-wise clickstream (e.g., a sequence of video plays and pauses, quiz submissions). We denote a clickstream in a course for a student as a time series with being the total number of interactions of student in course . Each interaction is represented by a tuple , including a timestamp , an action (videos: load, play, pause, stop, seek, speed; quiz: submit), and a learning object (video, quiz). Given the weekly course schedule, we assume that identifies the time where the course week ends, and that the clickstream of student generated until the end of the week can be denoted as . We also assume that the course schedule includes one or more assignments per week and that the grade record of student across course assignments is denoted as , where is the grade student received on the assignment in week . In the case of multiple graded assignments for a certain week, we considered the average score of graded assignments for that week and scored non-attempted assignments with . We denote as the success labelfor student .
2.2 Data Preprocessing
A significant portion of MOOC students enroll just to watch a few videos or find that the curriculum material is not what they expected and drop out of the course in the first weeks [32, 10]. It follows that it is easy to predict the success labels for this selection of students by simply looking at their initial few weekly assignment grades in . Therefore, optimizing complex deep learning models for predicting student success on early-dropout students is inefficient. Using these complex deep models also leads to less interpretable predictions in comparison with traditional models. For this subset of early-dropout students, traditional models can both achieve a comparable accuracy and still remain interpretable. To identify early-dropout students, we fit a Logistic Regression model on the assignment grades of the first two course weeks. The input data is the vector , where is the number of course weeks ( in our experiments) whereas the ground truth is the student success label . Once the model is fitted, we filter out the students that had a predicted probability of course failure . We determine the optimal threshold via a grid search over , maximizing the model balanced accuracy. Henceforth, we consider to be the student population obtained after the early-dropout student filtering.
2.3 Feature Extraction
As an input for our student success prediction models, we consider a set of behavioral features extracted for each student based on their interactions . We include four feature sets proved to have high predictive power for success prediction in MOOCs [26]. Given the size and variety of the course data considered in our study, we included all features of the four features sets, instead of considering only the specific features identified as important by at least one course [26]. Formally, given interactions generated by students until a course week , we create a matrix (i.e, each feature in the feature set is computed per student per week), where is the dimensionality of the feature set. We focus on the following behavioral aspects:
- Regularity features (, shape: ) monitor the extent to which a student follows regular study habits [4].
- Engagement features (, shape: ) monitor the extent to which a student is engaged in the course [6].
- Control features (, shape: ) measure the fine-grained video consumption per student [19].
- Participation features (, shape: ) monitor attendance on videos/quizzes based on the schedule [26].
We extract the above features for each student and concatenate features across sets to obtain the final combined behavioral features per student. The overall matrix of features is defined as , with ( denotes a concatenation). Due to the different scales, we perform a min-max normalization per feature in (i.e., we scale the feature between 0 and 1 considering all students and weeks for that feature). We elaborate on the most important features later on in the paper as highlighted by the analyses in subsequent experiments (e.g., Table 1).
| Set | Feature | Description |
|---|---|---|
Regularity | DelayLecture | The average delay in viewing video lectures after they are released to students. |
| RegPeakTimeDayHour | Regularity peak based on entropy of the histogram of user’s activity over time. | |
| RegPeriodicityM1 | The extent to which the hourly pattern of user’s activities repeats over days. | |
Engagement | AvgTimeSessions | The average of users’ time between subsequent sessions. |
| NumberOfSessions | The number of unique online sessions the student has participated in. | |
| RatioClicksWeekendDay | The ratio between the number of clicks in the weekend and the weekdays | |
| StdTimeSessions | The standard deviation of users’ time between subsequent sessions. | |
| TotalClicksProblem | The number of clicks that a student has made on problems this week. | |
| TotalClicksWeekend | The number of clicks that a student has made on the weekends. | |
| TotalTimeProblem | The total (cumulative) time that a student has spent on problem events. | |
| TotalTimeVideo | The total (cumulative) time that a student has spent on video events. | |
| StdTimeBetweenSessions | The standard deviation of the time between sessions of each user. | |
Control | AvgReplayedWeeklyProp | The ratio of videos replayed over the number of videos available. |
| AvgWatchedWeeklyProp | The ratio of videos watched over the number of videos available. | |
| FrequencyEventLoad | The frequency between every Video.Load action and the following action. | |
Participation | CompetencyAnticipation | The extent to which the student approaches a quiz provided in subsequent weeks. |
| ContentAlignment | The number of videos for that week that have been watched by the student. | |
| ContentAnticipation | The number of videos covered by the student from those that are in subsequent weeks. | |
| StudentSpeed | The average time passed between two consecutive attempts for the same quiz. |
2.4 Model Building
Given a course , we are interested in creating a success prediction model that can accurately predict the success label for student , given the extracted behavioral features . To this end, we rely on a neural architecture based on Bidirectional LSTMs, which can provide a good trade-off between effectiveness and efficiency2. The model input is represented by , i.e., the extracted behavior features, having a shape of . NaN values were replaced with the minimum score the student can receive for each respective feature. These features are then fed into a neural architecture composed by two simple yet effective BiLSTM layers of size 32 and 64 (loopback of ) and a Dense layer (with Sigmoid activation) having a hidden size of . The model outputs the probability the student will pass the course.
2.5 Explanation
Input behavioral features contribute with varying levels of importance to the prediction provided by a success prediction model. We unfortunately cannot examine the importance of these features directly, since deep neural networks act as black boxes. Explainability methods can therefore be adopted to approximate the contributions of each feature in towards the prediction associated with a specific student . To explore this aspect, we consider five instance-based explainability methods that are popular in the literature and cover different method families [22, 28]. We then compute the feature importance vector for each student , based on each explainability method. Formally, given an explainability method, we denote as the feature importance weights returned by the explainability method for student . The feature importance weight is a score, comparable across explainability methods, that represents the importance of feature to the model’s individual prediction for student . The considered explainability methods are described below.
LIME [36] trains a local linear model to explain each individual student instance .To this end, it first generates perturbed instances by shifting the feature values of a small amount. These new instances are then passed to the original model to get their associated predictions. Finally, a local interpretable model (e.g., a Support Vector Machine) is trained on the perturbed instances (input) and the corresponding predictions obtained from the original model (labels), weighting perturbed instances by proximity to the original instance. Mathematically, the local model can be expressed with the following equation:
(1)where is the instance being explained, is the family of all possible explanations, the loss that measures how close the predictions of the explainer are to the predictions of the original model , is the feature proximity measure, and represents the complexity of the local model. As LIME returns feature weights representing the feature influence on the final decision, we consider these absolute values to be the importance scores , and scale them to the interval , where indicates high importance.
KernelSHAP [24] draws inspiration from game-theory based Shapley values (computing feature contributions to the resulting prediction) and LIME (creating locally interpretable models). This SHAP variant uses a specially-weighted local linear regression to estimate SHAP values for any model. Let be the student instance being explained. A point in the neighborhood of is generated by first sampling a coalition vector . The coalition vector uses a binary mask to determine which features from will be kept the same in the new instance , and which will be replaced by a random value from the data distribution of that feature in . Feature importance weights for each new instance are calculated using a predefined kernel, after which the local model can be trained. A SHAP explanation is mathematically defined as:
(2)where is the local explainer, is the SHAP value (feature attribution) of feature , and is the coalition binary value. To achieve Shapley compliant weighting, Lundberg et al. [24] propose the SHAP kernel:
(3)where is the maximum coalition size and is the number of features present in coalition instance [28].
SHAP methods directly provide values representing the feature contribution to the prediction of instance . To obtain the importance scores , we apply the same transformation as LIME, by taking the absolute values of the SHAP feature attributions and scaling them to the interval .
PermutationSHAP (PermSHAP) [24] is very similar to the KernelSHAP formulation, but does not require the tuning of a regularization parameter or a kernel function. We made the decision to include both KernelSHAP and PermSHAP as a form of validation of our comparative evaluation analysis; the distance between two very similar SHAP methods is expected to be smaller than the distance between these SHAP methods and other families of explainability methods. PermSHAP approximates the Shapley values of features by iterating completely through an entire permutation of the features in both forward and reverse directions (antithetic sampling). To extract the feature importance vector , we again consider the absolute values of the SHAP feature attributions and scale to the interval .
Contrastive Explanation Method (CEM) [8] identifies which features need to be present (pertinent positives) or which features must be absent (pertinent negatives) in order to maintain the model prediction for a student with behavioral features [8]. For our setting, we consider pertinent negatives as they are intuitively more similar, and therefore comparable, to other counterfactual-based explainability methods. For each generated pertinent negative, we calculate the importance score for each feature by multiplying the absolute change from the value in the original instance to the value in the pertinent negative, modeled as the standard deviation () of that feature across all instances used for the experiment , as shown in the following formula:
(4)The importance score therefore takes into consideration both the necessary perturbation of the feature as well as the significance of the change relative to the feature range. We normalize the scores in the range , such that the resulting feature importance weights can be directly comparable.
Diverse Counterfactual Explanations (DiCE) [29] generates example instances to explain the model prediction as well. However, while CEM describes conditions necessary to keep the prediction unchanged, DiCE describes the smallest possible change to the initial instance that results in a different prediction. In other words, DiCE generates nearest neighbor counterfactual examples by optimizing the loss:
(5)where is a counterfactual example, is the total number of examples to be generated, is the black box ML model, is a metric that minimizes the distance between the prediction makes for and the desired outcome , is the original input with input features, and diversity is the Determinantal Point Process (DPP) diversity metric. and are hyperparameters that balance the three parts of the loss function. The stopping condition is convergence or 5000 time steps per counterfactual. Microsoft’s DiCE library [29] has a built-in function to compute local feature importance scores from the counterfactual instances, scaled in . We use them as feature importance weights .
| Title | Identifier | Topic | Level | Language | No. Weeks | No. Students | Passing Rate (%) |
No. Quizzes |
|---|---|---|---|---|---|---|---|---|
| Digital Signal Processing 1 | DSP 1 | CS | Bsc | French | 10 | 5629 | 26.8 | 17 |
| Digital Signal Processing 2 | DSP 2 | CS | MSc | English | 10 | 4012 | 23.1 | 19 |
| Éléments de Géomatique | Geomatique | Math | MSc | French | 15 | 452 | 45.1 | 27 |
| Villes Africaines | Villes Africaines | SS | BSc | English | 13 | 5643 | 9.9 | 17 |
| Comprendre les Microcontrôleurs | Micro | Eng | BSc | French | 13 | 4069 | 5.1 | 18 |
No. Students is calculated after filtering out the early-dropout students, as detailed in Sec. 2.2.
3. EXPERIMENTAL ANALYSIS
We evaluated the explainability methods on five MOOCs. We first explored how feature importance varies across different explainers for one specific course (RQ1). We then investigated the similarity of the explainability methods across the five courses using distance metrics (RQ2). Finally, we assessed the validity of the explainers using simulated data from a course with a known underlying prerequisite skill structure (RQ3). In the following sections, we describe the dataset and optimization protocol used for the experiments before explaining each experiment in detail.
3.1 Dataset
Our experiments are based on log data collected from five MOOCs of École Polytechnique Fédérale de Lausanne between 2013 to 2015. We chose the five courses to cover a diverse range of topic, level, and language. Table 2 describes the five courses in detail. We include two subsequent iterations of the same computer science course (DSP) with different student populations (French Bachelor students vs. English MSc students). Besides computer science, we also cover courses in the areas of mathematics (Geomatique), social sciences (Villes Africaines) and engineering (Micro). In total, the raw data set contained log data from 75,992 students. After removing the early-dropout students (see Sec. 2.2), 19,805 students remain in the data set. The smallest course contains students, while the largest course contains 5,643 students. Students’ log data consists of fine-grained video (e.g., play, pause, forward, seek) and quiz events (e.g., submit). Interaction data is fully anonymized with regards to student information, respecting participants’ privacy rights.
3.2 Experimental Protocol
For each course , we trained a BiLSTM model on features extracted from . For the optimization, we used batches of size , an Adam optimizer with an initial learning rate of , and a binary crossentropy loss. After an initial grid search3, we selected the same architecture for all models: two BiLSTM layers consisting of 64, 32 units and one Dense layer consisting of 1 unit with a Sigmoid activation. As this work is not focused on improving model performance, we did not tune hyperparameters further. Formally, we split the data of each course into a training data set ( of the students) and a test data set ( of the students). For each course, we performed a stratified train-test split over students’ pass/fail label. We then trained each model on the training data set and then predicted student success on the respective test data set . We chose the balanced accuracy (BAC) as our primary evaluation metric because of the high class imbalance of most of the selected courses.
For the first two experiments (RQ1 and RQ2) we used the student log data collected for the full duration of the course for training and prediction of our models. In the third experiment, we optimized models for different sequence lengths, i.e. using only the log data up to a specific week of the course (i.e. from week to week ) to predict performance in the assignment of course week . Additional replication details for model training can be found in Appendix B.
For all experiments, we applied the explainability methods to the predictions of the optimized models . All five methods are instance-based; they compute the feature importance based on the model predictions for a specific instance. Training explainers on the scale of thousands of students across five courses is not feasible due to the computation time required to generate the explanation for one instance (e.g., the counterfactual explainability methods take a computation time of 30 minutes per instance ). Therefore, we determined a representative sampling strategy to pick students from each course , resulting in explanations for students in total4. For the first two experiments (RQ1 and RQ2), we used a uniform sampling strategy to select the representative students for a course and ensured balance between classes (pass/fail). We first extracted all failing students and ordered them according to the predicted probability of the model . We then uniformly sampled failing students from this ordered interval. We repeated this exact same procedure to sample the passing students. This sampling procedure ensures that we include instances where the model is confident and wrong, instances for which the model is unsure, and instances where the model is confident and correct. For the last experiment (RQ3), we used performance in the assignment of a given week as the binary outcome variable. We then followed exactly the same uniform sampling procedure as for RQ1 and RQ2, ensuring class balance on assignment performance.
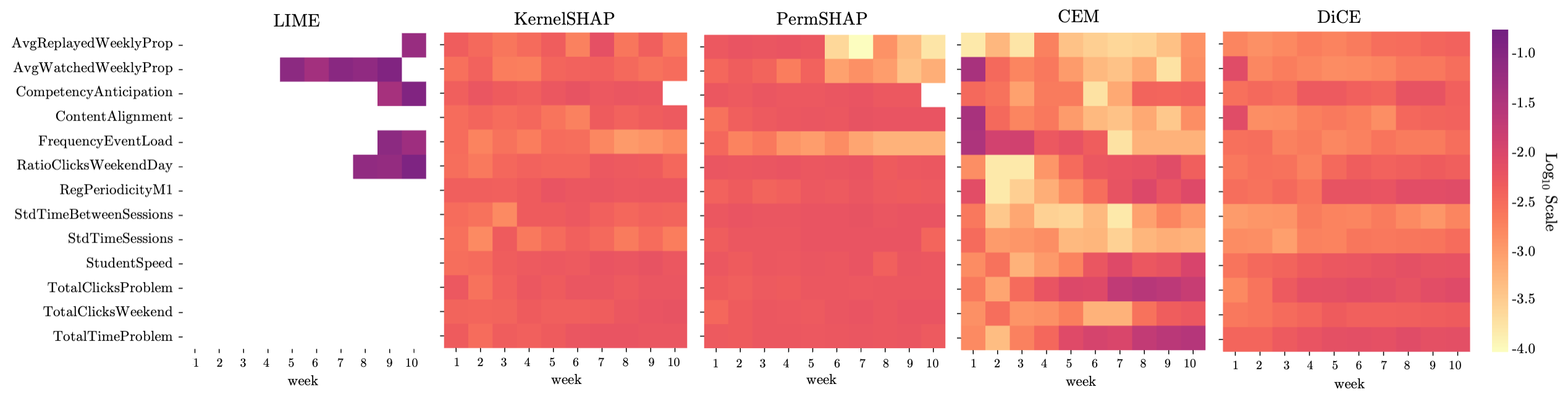
3.3 RQ1: Explanations for one course
In a first experiment, we compared the explanations of the instance-based methods for one specific course (DSP 1). The BiLSTM model trained on this course achieved a BAC of . We then ran the explainability methods on and extracted normalized feature importance scores for representative students of each course.
Figure 2 illustrates the features identified as most important by each explainability method. The heatmaps were computed by averaging importance scores for each feature and week across representative students for DSP 1 (see Sec. 3.2). To ensure interpretability of Figure 2, we only included the top five features for each method, resulting in distinct features. The description of all the features can be found in Table 1. We used a log scale within the heatmaps, with darker colors indicating higher feature importance.
We observe that the top features cover all the different behavioral aspects included in the feature set: Regularity, Engagement, Control, and Participation. However, some aspects seem to contain more important features. For example, of the Participation features ( out of features) are in the top five features of at least one method, while this is the case for only ( out of features) of the Control features. For Regularity and Engagement, and of the features get selected into the top feature set.
We also immediately recognize that the heatmap of LIME looks very different from the heatmaps of all the other methods. LIME assigned high importance scores to a small subset of features and weeks, while all the other explainability methods tend to identify more features and weeks as important, resulting in generally lower importance scores. We also observe that LIME does not consider student behavior in the first weeks of the course important; all importance is placed onto the second half of the course. Moreover, LIME seems to put more emphasis on Control than on the other three aspects: the features related to Control (AvgReplayedWeeklyProp, AvgWatchedWeeklyProp, FrequencyEventLoad) are important from week through week , while the features related to Participation (CompetencyAnticipation) and Engagement (RatioClicksWeekendDay) are important only during the last to weeks of the course.
Interestingly, while CEM and DiCE are both counterfactual methods, their heatmaps look quite different: the feature importance scores of DiCE tend to be more similar to KernelSHAP and PermSHAP than CEM. We note that CEM shows a higher diversity in feature importance scores than the other three methods (KernelSHAP, PermSHAP, and DiCE), for which the importance values seem to be quite equally distributed across the top features. Furthermore, in contrast to all the other explainability methods, CEM seems to also identify features in the first weeks of the course as important (e.g., AvgWatchedWeeklyProp, ContentAlignment, and FrequencyEventLoad in week ). In contrast to all the other methods, CEM identifies features related to being engaged in quizzes as relevant (TotalClicksProblem and TotalClicksWeekend). Finally, as expected, the heatmaps of KernelSHAP and PermSHAP look very similar, with only small differences in importance scores.
In summary, while there is some agreement on the top features across explainability methods (the union of the top five features of each method only contains distinct features), we observe differences across methods when it comes to exact importance scores.
3.4 RQ2: Comparing methods across courses
Our second analysis had the goal to quantitatively compare the explanations of the different methods across all five courses. Explainability method evaluation is an emerging field; most existing research focused on assessing the quality of explanations [38, 20] with only few works suggesting a quantitative ‘goodness’ score for each explainability method (e.g., [31, 43]). In contrast, we examined the distance between the feature importance scores per explainability method in comparison to each other, instead of individually. We first visualized the similarity of importances across courses using a Principal Component Analysis and then computed Spearman’s Rank-Order Correlation as well as Jensen-Shannon Distance to assess similarity regarding the feature importance ranking as well as their exact values.
Principal Component Analysis (PCA) We performed a PCA on the importance scores for each feature and week (length: ) separately for each explainability method and course . Figure 3 shows the results for all explainability methods and courses. Each marker in Figure 3 represents a specific course, while each color denotes an explainability method.
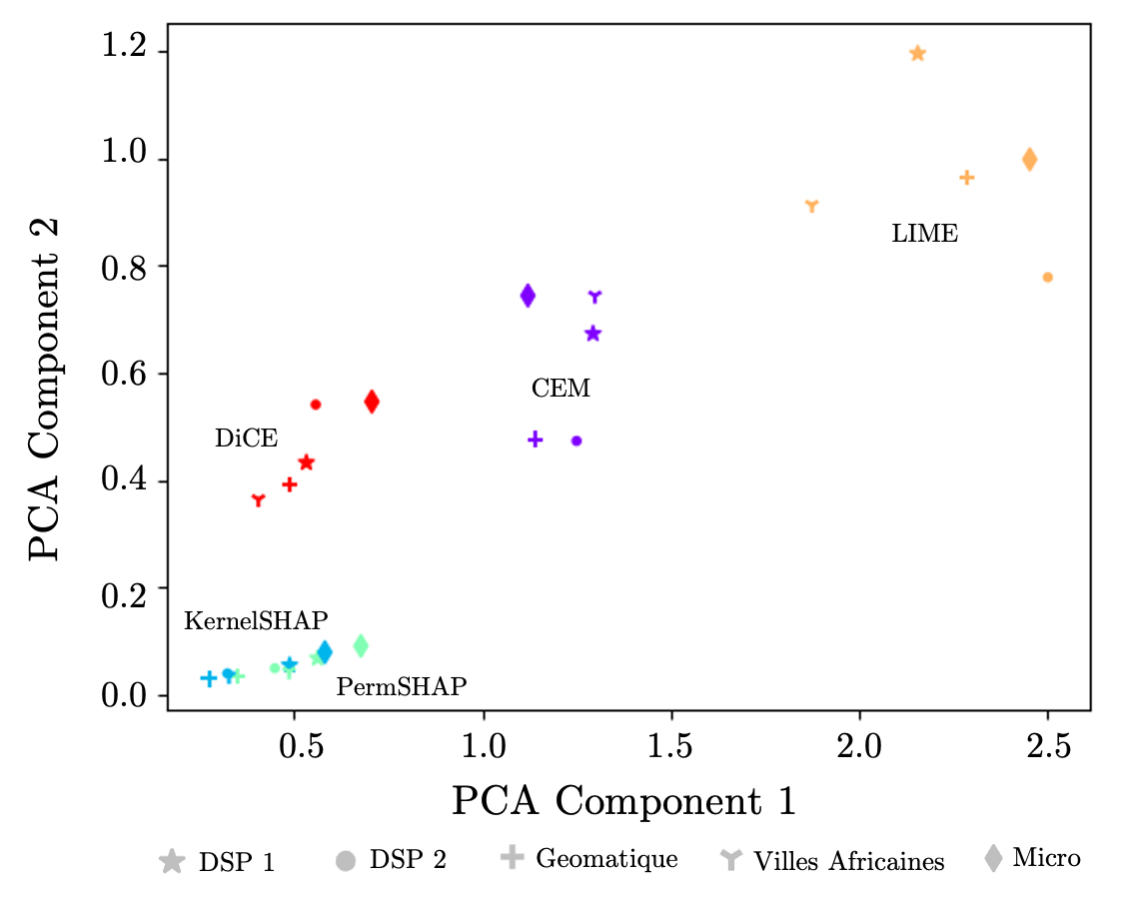

We observe that the two SHAP methods (KernelSHAP and PermSHAP) cluster together very strongly. This result is expected, as the methodologies of KernelSHAP and PermSHAP are very similar. DiCE feature importances are quite close to the SHAP methods, showing that the three methods have similar notions of feature importance. LIME is quite different from all other methods, with high values on both PCA components. Based on differences in methodology, we would have expected that the difference between the counterfactual methods (DiCE and CEM) and the SHAP methods would be larger than the difference between LIME and the SHAP methods. The most notable takeaway from Figure 3 is that there are clearly identifiable clusters based on explainability method and not on course. It therefore seems that the resulting feature importance scores are mainly influenced by the explainability rather than by the model or data (i.e. the characteristics of the course and students’ data).
Spearman’s Rank-Order Correlation. Often referred to as Spearman’s [39], this metric identifies the rank correlation (statistical dependence between the rankings) between two variables and is defined as the Pearson correlation coefficient between the rankings of two variables. We chose this metric for evaluating explainability methods to highlight the importance of feature ranking order in explanations. To compute Spearman’s Rank-Order Correlation between two explainability methods and on a course , we first converted the vectors and of feature importance scores (length ) for each student into rankings and . We then computed separately for each relevant student and then averaged over all relevant students to obtain .
Figure 4 illustrates the pairwise similarities between explainability methods using Spearman’s Rank-Order Correlation. Higher values imply stronger correlation between methods. We see similarities between KernelSHAP and PermSHAP prevalent once again as a center square for each course, affirming our intuition that two similar methodologies would result in similar rank-order scores. It can be observed that LIME consistently shows rank-order correlation scores with all other explainability methods. Additionally, for DSP 1 and to some degree also Villes Africaines, DiCE is much closer to KernelSHAP and PermSHAP then to CEM. For DSP 2 and Geomatique, DiCE and CEM are both equally correlated to the SHAP methods, but less correlated among themselves. Finally, the model trained on Micro has strong correlations across all explainability methods except LIME.
Jensen-Shannon Distance. We used the Jensen-Shannon distance [21] to compute pairwise distances between exact feature importance score distributions obtained with different explainability methods. The Jensen–Shannon distance is the square root of the Jensen-Shannon divergence, originally based on the Kullback–Leibler divergence with smoothed values. It is also known as the Information Radius (IRad) [25]. To compute the Jensen-Shannon distance between two explainability methods and on a course , we first calculated the distance between the feature importance scores (length ) and separately for each representative student and then averaged across all representative students to obtain .
Figure 5 shows the pairwise distance between explainability methods for all courses using Jensen-Shannon Distance. Larger numbers represent higher dissimilarity. The Jensen-Shannon Distance heatmaps confirm the observations made using Spearman’s Rank-Order Correlation (see Figure 4). Again, LIME consistently has a high distance to all other explainability methods across all courses. As expected, KernelSHAP and PermSHAP have low pairwise distances for all courses. However, when comparing feature importance scores directly instead of using rankings, we observe even less differences between courses. DiCE is closer across all courses to the SHAP methods than CEM. While LIME exhibits the highest distances to all other explainability methods, the explanations of CEM are also far away from all methods.
In summary, the two SHAP methods and DiCE seem to deliver the most similar explanations, while the feature importance scores obtained with CEM and LIME are different from the other explainability methods. More importantly, all our analyses (PCA, Spearman’s Rank-Order Correlation, Jensen Shannon Distance) demonstrate that the choice of explainability method has a much larger influence on the obtained feature importance score than the underlying model and data.
3.5 RQ3: Validation of explanations
The previous experiments delved into mapping the similarities and differences between explainability methods. While our analyses demonstrated that there are clear disparities across method choice, they do not give an indication regarding the ‘goodness’ of the obtained explanations. Recent work discusses traits of ideal explanations [5] and targets metrics to measure explanation quality [43, 15]. However, these metrics tend to be over-specialized to one explainability method over others due to the similarities in their methodologies. The community does not yet have a set of standard metrics for evaluating explainability methods. In our last experiment, we hence use information inherent to our model’s setting to perform an initial validation of the explanations provided by the different methods.
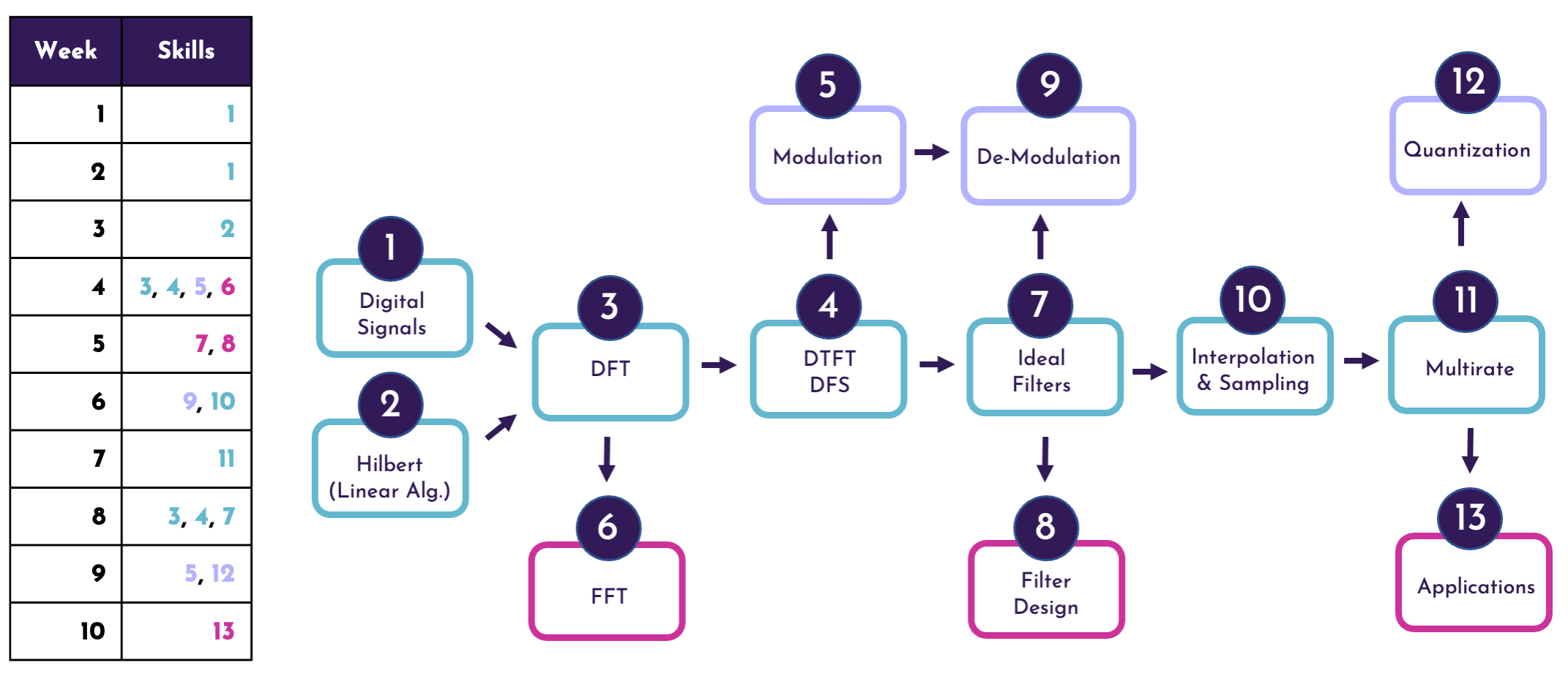
Specifically, we evaluated the explainability methods on a course with a known underlying skill map and used the prerequisite relationships between weeks of the course as a ground truth for the explanations. Based on the results obtained for the first two research questions (Sections 3.3 and 3.4), we selected one representative method from each methodological group for the analysis, while keeping the observed explanation diversity: PermSHAP (the most widely used SHAP method), CEM (chosen as a representative of counterfactuals for its further disparity from the SHAP methods), and LIME. In terms of courses, we used DSP 1 as a basis for the analysis as the instructor of this course provided us with the skill map derived from the curriculum.
Figure 6 illustrates the underlying skills, their relationships, as well as their mapping to the weeks of the course. The arrows denote the prerequisite relationships, while the numbers denote the unique skills in the order they are introduced in the course. The skills colored in pink (, , and ) refer to applied skills learned in the course. The middle track refers to core skills learned in the course (colored in blue) and the purple skills at the top (, , and ) are theory-based extensions of core material. The skill prerequisite map allows us to analyze the dependencies between the different weeks of the course. For example, in order to understand Modulation taught in week , students need to already have learned the skills taught in weeks and (DFT, DTFT, and DFS). Intuitively, a model predicting performances in assignments in week would have highly correlated features based on week . We assume that these dependencies would logically be uncovered by the explainability method.
We, therefore, adjusted our predictive task: using the optimization protocol and experimental design described in Section 3.2, we aimed at predicting the performance (binary label: below average or above average) of a student in the assignment of week based on features extracted from student interactions for weeks to . Given the prerequisite structure for the course, we ran experiments for . For each predictive model , we then picked the representative students using uniform sampling and taking into account class balance (see Section 3.2 for a detailed description of the sampling procedure) and applied the selected explainability methods to these representative instances.
Figure 7 shows the features for LIME, PermSHAP, and CEM for the prediction model of week . In the heatmap, darker values indicate a higher score. The scores for the heatmap have been computed based on a ranking of features and weeks: for each student , we first ranked the features in order of feature importance as determined by the respective explainability method. We then scored each of the top features according to its rank: points for the top feature, points for the second most important feature, and so on. Finally, we averaged the scores for each feature across the representative students through and normalized them. This rank-based scoring allows us to compare explainability methods without having the relative feature importance scores bias the analysis. We only selected features with a score of at least in any course week, showing only the top two-thirds of features per method.
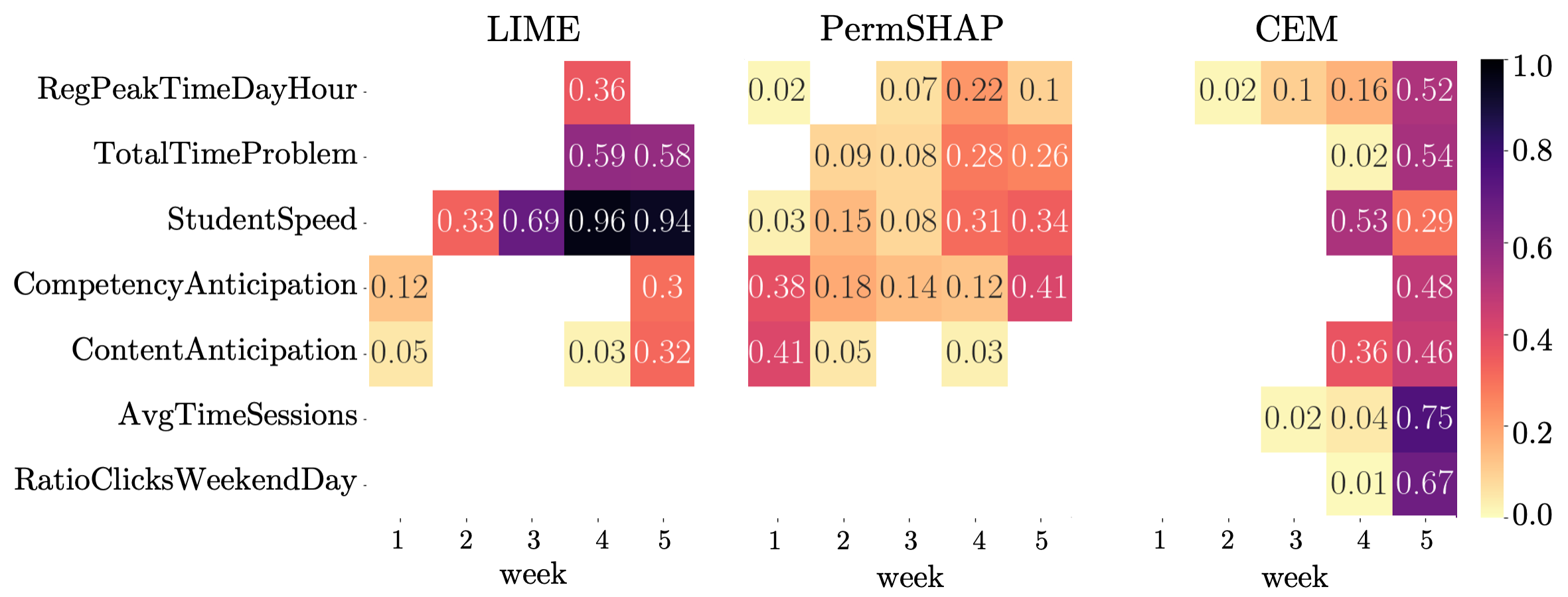
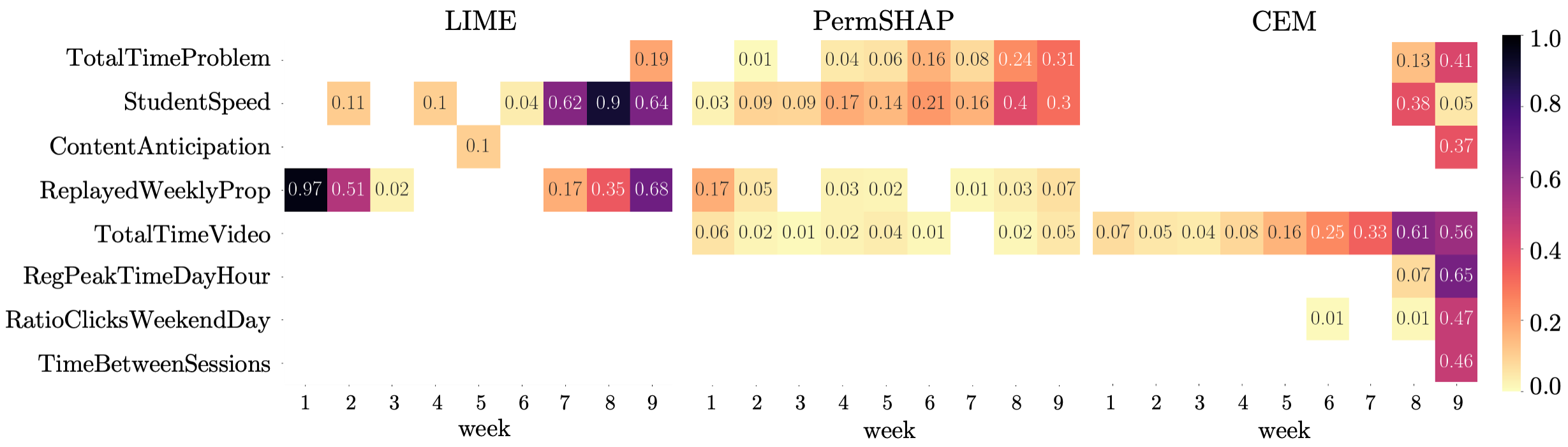
For LIME, we observe that four features have been identified as important for predicting assignment performance in week . Two of these features directly relate to student behavior on the week assignment: TotalTimeProblem (the total time the student spent solving the assignment) and StudentSpeed (the time between consecutive trials of assignments). The high scores of these features for week are thus expected. LIME also assigns high scores to these two assignments based features for week . This result is encouraging as week teaches the prerequisite skills of week and therefore, LIME seems to (at least partially) uncover the prerequisite structure of the course.
In PermSHAP results, we see again that the scores are more uniformly distributed across features and weeks. However, we observe again that the assignment-based features (TotalTimeProblem and StudentSpeed) have comparably high scores for week and therefore PermSHAP also seems to (partially) uncover the prerequisite relationships. Curiously, watching videos and solving quizzes scheduled for subsequent weeks (CompetencyAnticipation and ContentAnticipation) is also considered important, hinting that being proactive when learning increases learning success.
CEM seems to be able to partially uncover the prerequisite relationship between weeks as well. For week , one feature related to assignment behavior (StudentSpeed) exhibits a high score. Additionally, watching content of the subsequent week (in this case, week ’s ContentAnticipation for week material) is important for assignment performance. Otherwise, CEM mainly explains performance in the assignment of week with student behavior in week : besides the assignment-related features, the students’ actions in the inference week are considered important.
Figure 8 shows the importance scores for LIME, PermSHAP, and CEM for the prediction model of week . Again, darker colors in the heatmaps indicate higher scores. The scores in the heatmaps were computed using the same ranking-based procedure as for Figure 7. In week , Figure 6 indicates that weeks and cover the prerequisite skills. From Figure 8, we observe that LIME does not seem to be able to capture this prerequisite relationship. The top scores for LIME appear in week itself for an assignment-based feature (StudentSpeed) as well as for video control behavior (AvgReplayedWeeklyProp, which computes the relative number of video replays). Furthermore, StudentSpeed seems to be generally important also in the weeks just before the predicted week (weeks and ). For PermSHAP, we again obtain a more equal distribution, with only the two assignment-related features (TotalTimeProblem and StudentSpeed) in weeks and showing relatively higher scores. Furthermore, PermSHAP also assigns relatively higher importance to these features for week , which is a prerequisite for week . For CEM, we again observe that mainly student behavior in the actual week, i.e. week , seems to explain assignment performance. Only one feature (TotalTimeVideo) shows medium importance for weeks and .
In summary, all the evaluated methods were able to (partially) detect the prerequisite relationship between week and week . For week , detecting the prerequisite structure proved to be difficult; results differed between methods. However, we should take into account that none of the features of the feature set directly measure student performance and therefore, the generated explanations rely on behavioral features only. It appears that recent and actual behavior is a much stronger indicator for performance than past behavior.
4. DISCUSSION AND CONCLUSION
Explainability methods allow us to interpret a deep model in a way that is understandable not only to machine learning experts, but also end-users of educational environments, including instructors tailoring course designs and students the model is predicting on [41, 7]. In this paper, we aimed to understand explainers’ behaviour and the ways in which they differ for the task of student success prediction.
Our results demonstrate that all explainability methods can derive interpretable motivations behind student success predictions, confirming the similar yet coherent observations made by [23] for the knowledge tracing field. However, while there was some agreement regarding the top features across the five explainability methods, key differences across methods emerged when we considered the exact importance scores (RQ1). We observed substantial similarities between KernelSHAP, PermSHAP, CEM and DiCE with regards to the top ranked feature-weeks. Conversely, LIME only ranked very few features as important, and these less important feature similarities made the other explainability methods appear closer to each other. Overall, looking beyond top ranked features, we noted considerable differences in feature importances across explainability methods. Interestingly, LIME-detected features are more in line with the features marked as important by Random Forests in [26], still in a MOOC context. This observation further demonstrates the generalizability of the features’ predictive power even among very different experimental settings.
In a subsequent experiment, we compared the different explainability methods across five MOOCs. Our findings indicate that the choice of explainability method has a much larger influence on the obtained feature importance score than the underlying model and data (RQ2). With distance (Jensen-Shannon distance) and ranking-based metrics (Spearman’s Rank-Order Correlation), we uncovered that LIME is farthest from the other explainability methods. The sparsity of LIME-detected important features was also observed by [37], where the conciseness of LIME explanations supported integration in visual dashboards for student advising. We also detected a close relationship between KernelSHAP and PermSHAP, which strongly validates our evaluation strategy. Using PCA, we identified clear clusters of explanations by explainability method and not by the course the model was trained upon, suggesting that an explainability method might be prone to mark specific features as important regardless of the model (and the course).
Our analyses also confirmed that all the evaluated methods were able to (partially) detect the prerequisite relationship between weeks, while relying on behavioral features only (RQ3). Our experimental design was inspired by [30]’s work on predicting effectiveness of interventions for wheel-spinning students by simulating prerequisite relationships. While we have no way to examine the true underlying feature importances of our week assignment performance prediction model, we intuit that a student’s prerequisite week performance should be important to predicting their performance in week . We observed that the three families of methods (LIME, SHAP, and counterfactual) were able to partially capture the prerequisite relationship in week , but struggled to capture the prerequisite relationships in week . While there were few similarities in the top ranked features, each method found different groups of feature-weeks as most important for the same models. Our results indicate that recent and current behavior is more important than past behavior, implying that proximity of behavioural features correlates strongly with their perceived importance. A limitation is that the prerequisite relationships we deem important might not actually be used as the true features of the model since our feature set included only features that examined student behavior and not direct performance.
Our results indicate that there are noteworthy differences in generated explanations for student performance prediction models. However, our analyses also show that these explanations often recognize prerequisite-based relationships between features. That being said, our study still has several limitations that warrant future research, including our focus on a singular downstream task (student success prediction), specific modality of dataset (MOOCs), choice of model architecture (BiLSTM), and lack of assessment of the obtained explanations’ impact in the real world. First, extending our experiments beyond success prediction to a multi-task analysis (e.g., dropout prediction) across multiple modalities (e.g., flipped classrooms, intelligent tutoring systems) would allow us to build stronger intuitions about explainability method differences. Second, extending our black-box BiLSTM model architecture to multiple traditional and deep machine learning architectures could examine whether certain explainability methods have stronger explanation affinity to different predictors. Choosing transparent shallow architectures instead of black-boxes could also allow us to validate our results against ground truth feature importances. Third, further research should be conducted to check which explanations (and explainability methods) lead to interventions that better improve learning outcomes. It follows that an assessment of the obtained explanations should be carried out involving educators. Finally, the disagreement of our selected explainability methods motivate an extension in an ensemble expert-weighting scheme, which might have merit in closely estimating the true feature importances.
Explainability in educational deep learning models can lead to better-informed personalized interventions [42, 16], curriculum personalization, and informed course design. If we were considering global interventions (as it might be too resource intensive to perform interventions on each student individually), we could take the mean feature importance vector over all students and try interventions in the order of the scores of this mean vector. If we were only able to intervene on features due to resource constraints, Spearman’s rank-order metric could also be modified to include the size of the intersection between the features with the top scores. However, it is important to note that when the model explanations are biased by explainability method and do not accurately reflect the inner workings of the model, the impact of incorrect predictions are further exacerbated by teachers and students’ misplaced confidence in the model’s justification. We implore data scientists to not take the choice of explainability method lightly as it does have a significant impact on model interpretation, and instead urge the community to (1) carefully select an appropriate explainability method based on a downstream task and (2) keep potential biases of the explainer in mind when analyzing interpretability results. Overall, our work contributes to ongoing research in explainable analytics and to the generalization of theories and patterns in success prediction.
5. ACKNOWLEDGMENTS
We thank Professor Paolo Pardoni, Valentin Hartmann, and Natasa Tagasovska for their expertise and support.
6. REFERENCES
- M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, et al. TensorFlow: A system for Large-Scale machine learning. In 12th USENIX symposium on operating systems design and implementation (OSDI 16), pages 265–283, 2016.
- G. Abdelrahman and Q. Wang. Knowledge tracing with sequential key-value memory networks. In 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 175–184, 2019.
- M. Baranyi, M. Nagy, and R. Molontay. Interpretable deep learning for university dropout prediction. In 21st Annual Conference on Information Technology Education, pages 13–19, 2020.
- M. S. Boroujeni, K. Sharma, Ł. Kidziński, L. Lucignano, and P. Dillenbourg. How to quantify student’s regularity? In European conference on technology enhanced learning, pages 277–291. Springer, 2016.
- D. V. Carvalho, E. M. Pereira, and J. S. Cardoso. Machine learning interpretability: A survey on methods and metrics. Electronics, 8(8):832, 2019.
- F. Chen and Y. Cui. Utilizing student time series behaviour in learning management systems for early prediction of course performance. Journal of Learning Analytics, 7(2):1–17, 2020.
- C. Conati, K. Porayska-Pomsta, and M. Mavrikis. AIin education needs interpretable machine learning: Lessons from open learner modelling. 2018.
- A. Dhurandhar, P.-Y. Chen, R. Luss, C.-C. Tu, P. Ting, K. Shanmugam, and P. Das. Explanations based on the missing: Towards contrastive explanations with pertinent negatives. Advances in Neural Information Processing Systems, 31, 2018.
- A. Ferreira, S. C. Madeira, M. Gromicho, M. d. Carvalho, S. Vinga, and A. M. Carvalho. Predictive medicine using interpretable recurrent neural networks. In International Conference on Pattern Recognition, pages 187–202. Springer, 2021.
- J. Goopio and C. Cheung. The mooc dropout phenomenon and retention strategies. Journal of Teaching in Travel & Tourism, 21(2):177–197, 2021.
- Y. Goyal, Z. Wu, J. Ernst, D. Batra, D. Parikh, and S. Lee. Counterfactual visual explanations. In International Conference on Machine Learning, pages 2376–2384. PMLR, 2019.
- A. Gramegna and P. Giudici. Shap and lime: An evaluation of discriminative power in credit risk. Frontiers in Artificial Intelligence, 4, 2021.
- K. M. Hasib, F. Rahman, R. Hasnat, and M. G. R. Alam. A machine learning and explainable AIapproach for predicting secondary school student performance. In IEEE 12th Annual Computing and Communication Workshop and Conference, pages 0399–0405, 2022.
- A. S. Imran, F. Dalipi, and Z. Kastrati. Predicting student dropout in a MOOC: An evaluation of a deep neural network model. In 5th International Conference on Computing and Artificial Intelligence, pages 190–195, 2019.
- Y. Jia, E. Frank, B. Pfahringer, A. Bifet, and N. Lim. Studying and exploiting the relationship between model accuracy and explanation quality. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 699–714. Springer, 2021.
- A.-H. Karimi, B. Schölkopf, and I. Valera. Algorithmic recourse: from counterfactual explanations to interventions. In ACM Conference on Fairness, Accountability, and Transparency, pages 353–362, 2021.
- G. J. Katuwal and R. Chen. Machine learning model interpretability for precision medicine. arXiv preprint arXiv:1610.09045, 2016.
- J. Klaise, A. Van Looveren, G. Vacanti, and A. Coca. Alibi explain: algorithms for explaining machine learning models. Journal of Machine Learning Research, 22(181):1–7, 2021.
- S. Lallé and C. Conati. A data-driven student model to provide adaptive support during video watching across MOOCs. In International Conference on Artificial Intelligence in Education, pages 282–295. Springer, 2020.
- D. B. Leake. Evaluating explanations: A content theory. Psychology Press, 2014.
- J. Lin. Divergence measures based on the shannon entropy. IEEE Transactions on Information theory, 37(1):145–151, 1991.
- P. Linardatos, V. Papastefanopoulos, and S. Kotsiantis. Explainable AI: A review of machine learning interpretability methods. Entropy, 23(1):18, 2020.
- Y. Lu, D. Wang, Q. Meng, and P. Chen. Towards interpretable deep learning models for knowledge tracing. In International Conference on Artificial Intelligence in Education, pages 185–190. Springer, 2020.
- S. M. Lundberg and S.-I. Lee. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems, 30, 2017.
- C. Manning and H. Schutze. Foundations of statistical natural language processing. MIT press, 1999.
- M. Marras, J. T. T. Vignoud, and T. Kaser. Can feature predictive power generalize? benchmarking early predictors of student success across flipped and online courses. In 14th International Conference on Educational Data Mining, pages 150–160, 2021.
- D. Martens and F. Provost. Explaining data-driven document classifications. Management Information Systems Quarterly, 38(1):73–100, 2014.
- C. Molnar. Interpretable Machine Learning. 2nd edition, 2022.
- R. K. Mothilal, A. Sharma, and C. Tan. Explaining machine learning classifiers through diverse counterfactual explanations. In Conference on Fairness, Accountability, and Transparency, pages 607–617, 2020.
- T. Mu, A. Jetten, and E. Brunskill. Towards suggesting actionable interventions for wheel-spinning students. International Educational Data Mining Society, 2020.
- A.-p. Nguyen and M. R. Martínez. On quantitative aspects of model interpretability. arXiv preprint arXiv:2007.07584, 2020.
- D. F. Onah, J. Sinclair, and R. Boyatt. Dropout rates of massive open online courses: behavioural patterns. 6th International Conference on Education and New Learning Technologies, 1:5825–5834, 2014.
- M. Pawelczyk, K. Broelemann, and G. Kasneci. Learning model-agnostic counterfactual explanations for tabular data. In The Web Conference, pages 3126–3132, 2020.
- B. Pei and W. Xing. An interpretable pipeline for identifying at-risk students. Journal of Educational Computing Research, page 07356331211038168, 2021.
- C. Piech, J. Bassen, J. Huang, S. Ganguli, M. Sahami, L. J. Guibas, and J. Sohl-Dickstein. Deep Knowledge Tracing. Advances in Neural Information Processing Systems, 28, 2015.
- M. T. Ribeiro, S. Singh, and C. Guestrin. "Why Should I Trust You?": Explaining the predictions of any classifier. In 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144, 2016.
- H. Scheers and T. De Laet. Interactive and explainable advising dashboard opens the black box of student success prediction. In European Conference on Technology Enhanced Learning, pages 52–66. Springer, 2021.
- K. Sokol and P. Flach. Explainability fact sheets: a framework for systematic assessment of explainable approaches. In Conference on Fairness, Accountability, and Transparency, pages 56–67, 2020.
- C. Spearman. The proof and measurement of association between two things. 1961.
- A. Vultureanu-Albişi and C. Bădică. Improving students’ performance by interpretable explanations using ensemble tree-based approaches. In IEEE 15th International Symposium on Applied Computational Intelligence and Informatics, pages 215–220. IEEE, 2021.
- M. E. Webb, A. Fluck, J. Magenheim, J. Malyn-Smith, J. Waters, M. Deschênes, and J. Zagami. Machine learning for human learners: opportunities, issues, tensions and threats. Educational Technology Research and Development, 69(4):2109–2130, 2021.
- W. Xing and D. Du. Dropout prediction in MOOCs: Using deep learning for personalized intervention. Journal of Educational Computing Research, 57(3):547–570, 2019.
- J. Zhou, A. H. Gandomi, F. Chen, and A. Holzinger. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics, 10(5):593, 2021.
APPENDIX
A. MODEL ARCHITECTURE
We experimented with traditional machine learning models (e.g., Support Vector Machines, Logistic Regression, Random Forest) and deep-learning models (e.g., Fully-Connected Networks, RNNs, LSTMs, CNNs, and BiLSTMs), and found that BiLSTM models perform best against the other baselines for our use case. To determine the optimal model architecture, we evaluate validation set performance on the course DSP 1 as it is used in all three RQs. BiLSTMs have a average increase in balanced accuracy over traditional machine learning methods. For the BiLSTM architecture grid search, we examined the following layer settings {32, 64, 128, 256, 32-32, 64-32, 128-32, 128-64, 128-128, 256-128, 64-64-32, 128-64-32, 64-64-64-32-32} before determining 64-32 performed best in balanced accuracy for DSP 1. We used the Tensorflow library to train our models [1].
B. MODEL TRAINING
Model training took approximately 35 minutes per model on an Intel Xeon E5-2680 CPU with 12 cores, 24 threads, and 256 GB RAM. Each model was trained for 15 epochs, and the best performing model checkpoint was saved. The five models’ performance metrics are showcased in Table 3.
C. SAMPLING STRATEGY
We experimented with several strategies to extract a appropriate representative sample including the greedy algorithm SP-LIME [36], random sampling, two sets of extreme students (those which the model predicts very well on and very badly on), and uniform sampling. We determined that our uniform sampling approach was the most fair with respect to the variable class imbalance between courses.
| Identifier | Accuracy | Balanced Accuracy | F-1 Score |
|---|---|---|---|
| DSP 1 | 99.3 | 97.4 | 99.6 |
| DSP 2 | 99.1 | 93.5 | 99.5 |
| Geomatique | 97.7 | 96.2 | 98.7 |
| Villes Africaines | 98.4 | 95.5 | 99.1 |
| Micro | 89.5 | 90.9 | 90 |
1http://github.com/epfl-ml4ed/evaluating-explainers
2Experimental details can be found in Appendices A and B.
3Grid search is discussed further in Appendix A.
4Sampling strategy is discussed further in Appendix C.
© 2022 Copyright is held by the author(s). This work is distributed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) license.